I realized near the end of that post that I had completely screwed it up. I think some of the intent was conveyed, but not really what I wanted. I'm going to try it again.
New sample tables: ONLINE_STORES and ONLINE_STORE_STATUS.
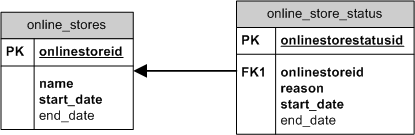
ONLINE_STORES has 4 columns:
- ONLINESTOREID - sequence generated surrogate key
- NAME - String, can be anything really
- START_DATE - When this store went online
- END_DATE - When this store went offline
- ONLINESTORESTATUSID - sequence generated surrogate key
- ONLINESTOREID - FK referencing ONLINE_STORES PK
- REASON - Why was the store de-activated or brought down. Typically I would supply a list of known reasons, but it's unnecessary for my purposes.
- START_DATE - Time the online store was de-activated.
- END_DATE - Time the online store was re-activated.
Similar to the example from Part I, you could do this (find an online store's status) another way be storing the status inline in ONLINE_STORES. Add a column (Persist) STATUS with a check constraint that limits the values to either UP or DOWN, along with a NOT NULL constraint of course.
In a pure OLTP environment that is probably the most efficient solution. Reporting on down times, or better, how long has an online store been UP, is sometimes an afterthought. This can be handled by a shadow/history/audit/logging table. Those have always felt clunky to me.
Many systems are a hybrid of OLTP and reporting (DW/DSS/etc.). My approach has been to tie the two tables together using a View (Derive) to get the answer to whether an online store is UP or DOWN. There might even be a name for that in the modeling books...I should read up.
Here are the scripts necessary for my demo:
CREATE TABLE online_storesNow I just create a simple View on top of these 2 tables:
(
onlinestoreid NUMBER(10)
CONSTRAINT pk_onlinestoreid PRIMARY KEY,
name VARCHAR2(100)
CONSTRAINT nn_name_onlinestores NOT NULL,
start_date DATE DEFAULT SYSDATE
CONSTRAINT nn_startdate_onlinestores NOT NULL,
end_date DATE
);
CREATE TABLE online_store_status
(
onlinestorestatusid NUMBER(10)
CONSTRAINT pk_onlinestorestatusid PRIMARY KEY,
onlinestoreid
CONSTRAINT fk_onlinestoreid_oss REFERENCES online_stores( onlinestoreid )
CONSTRAINT nn_onlinestoreid_oss NOT NULL,
reason VARCHAR2(100)
CONSTRAINT nn_reason_oss NOT NULL,
start_date DATE DEFAULT SYSDATE
CONSTRAINT nn_startdate_oss NOT NULL,
end_date DATE
);
INSERT INTO online_stores
( onlinestoreid,
name )
VALUES
( 1,
'online store #1' );
INSERT INTO online_stores
( onlinestoreid,
name )
VALUES
( 2,
'nerds r us' );
INSERT INTO online_stores
( onlinestoreid,
name )
VALUES
( 3,
'geeks rule' );
CJUSTICE@TESTING>SELECT * FROM online_stores;
ONLINESTOREID NAME START_DAT END_DATE
------------- --------------- --------- ---------
1 online store #1 30-JUL-09
2 nerds r us 30-JUL-09
3 geeks rule 30-JUL-09
3 rows selected.
CREATE OR REPLACECreate a record in ONLINE_STORE_STATUS:
VIEW vw_active_stores
AS
SELECT
os.onlinestoreid,
os.name,
os.start_date,
os.end_date
FROM online_stores os
WHERE NOT EXISTS ( SELECT NULL
FROM online_store_status
WHERE onlinestoreid = os.onlinestoreid
AND ( end_date IS NULL
OR SYSDATE BETWEEN start_date AND end_date ) );
INSERT INTO online_store_statusSelect from the View:
( onlinestorestatusid,
onlinestoreid,
reason )
VALUES
( 1,
1,
'maintenance' );
CJUSTICE@TESTING>SELECT * FROM vw_active_stores;Voila! I Derived!
ONLINESTOREID NAME START_DAT END_DATE
------------- --------------- --------- ---------
3 geeks rule 30-JUL-09
2 nerds r us 30-JUL-09
As a brief sanity check, I created a record that had a pre-determined re-activation date (1 hour forward).
INSERT INTO online_store_statusI'm really not sure which way is better/worse, as with anything I guess "It depends." The semaphore (flag) in ONLINE_STORES is a perfectly viable solution. It is the easiest solution, admittedly. Part of my thinking as well, and this relates back to the question I posed once before, UPDATEs in OLTP: A Design Flaw?. If I UPDATE the record in ONLINE_STORES, it has meaning. Typically it would either be to change the name or set the END_DATE. The UPDATE in ONLINE_STORE_STATUS means something else, it's just telling me the stop time of the DOWN time.
( onlinestorestatusid,
onlinestoreid,
reason,
start_date,
end_date )
VALUES
( 2,
2,
'the geek sliced us...',
SYSDATE - ( 1 / 24 ),
SYSDATE + ( 1 / 24 ) );
CJUSTICE@TESTING>SELECT * FROM vw_active_stores;
ONLINESTOREID NAME START_DAT END_DATE
------------- --------------- --------- ---------
3 geeks rule 30-JUL-09
1 row selected.
Or I am just overthinking this? Is this too much idealism? Is it idealism at all?I've talked about it so much lately I can't remember which way is up. What do you do?



















