Eleven days out now...I'm still a bit bummed that I won't get to attend.
I have been...well, I can't help, but follow along.
What To Do?
There should be more than enough to do while there. A full week of learning, networking, schwag, boozing...I mean networking.
Wow, how could I forget...the Appreciation Event. Aerosmith, Three Dog Night, Roger Daltrey, Shooter Jennings and The Wailers (of Bob Marley fame). (Thanks Justin for reminding me).
Joe D'Alessandro, President and CEO of the San Francisco Convention & Visitors Bureau located just steps from Moscone Center, lists the top 10 things to do around the Moscone Center. Part I is here, Part II is here.
Alex Gorbachev is organizing the Blogger Meet-up. Strangely, I have heard/read hardly a peep about bloggers that are going on the blogger pass. I'm pretty sure Fuad Arshad is going on the pass...but that's the only one I am aware of. I don't doubt there are others...just haven't seen any related posts or tweets to that effect.
Chris Muir is helping to organize the ADF Enterprise Methodology Group Meet-up. Chris informs me that Siman Haslam is doing much of the work.
Bob Rhubart has the enterprise architects, Enterprise Architecture Meet-Up
Update
Not sure how I missed the Apex meet-up...find information here. I'll definitely miss that one as I believe almost all of those guys and gals owe me beer.
Unconference, which seems to have become quite popular since it's inception in 2007.
Sessions
Application Express, my how that has grown since I began using it in 2005. WIN!
How about something on Solaris? Anything from Sun?
Coherence?
Some XMLDB from Marco Gralike?
BI Publisher
The CRM blog lists out all of their sessions by...ummm...everything:
Communications
Business Intelligence
Insurance
Financial Services
Sales Productivity
Public Sector
Education and Research
Exadata events can be found here (pdf).
Here is the OOW 09 page on the Oracle Wiki. Of course much of this information can be found via the official Oracle OpenWorld blog.
Finally, check out OpenWorld Live if, like me, you won't be attending. Looks like there are some pretty cool sessions to check out there as well.
Wednesday, September 30, 2009
Tuesday, September 29, 2009
Database Cleanup: Metrics
Before my current refactor/redesign goes to production, I would like to capture some metrics. I'm fairly limited in what I can actually do (i.e. I can't use DBMS_PROFILER in production).
So far, this is what I have come up with:
1. Lines of Code (LOC) - I don't believe this is necessarily a reflection of good or bad code. For instance, I can take that 2 line INSERT statement and turn it into 20 lines.
Was
In my opinion, when more than one person is going to support the code, readability is a nice thing. Whether or not you like my style, it is (more) readable. So LOC is not necessarily a great metric, but it can give you an idea which way you are going (after it has been properly formatted anyway).
2. COMMITs - Many argue that there should (almost) never be commits (an exception is logging with the AUTONOMOUS_TRANSACTION pragma) in the database. The calling application should perform the commits. Unfortunately that general rule is not always followed. I've added it to my list of metrics because it is pertinent to our environment. Of course I have gone to great pains to make sure that the removal of one commit will not impact the entire system...that possibility does exist when you have commits everywhere.
3. Text - This was a real stretch. What is the size of the individual procedure, package or function? I wouldn't have considered it (I never have until now), but I was desperate to define something...anything. How do you determine that?
4. Dependencies - Also known, to me, as modular code. Why have 200 INSERT statements into a single table when you could wrap that up into a single procedure and call that? If you add a column, you'll still have to go through and fix all those occurences (if it's not defaulted to something). But if you remove a column from that table, it can easily be hidden from the calling code, thus you only have to change it in one place. Of course you wouldn't want to leave it there forever, but it can be done piece-meal, bit by bit as you work on affected parts.
Have you ever thought about this before? What kind of metrics would you suggest? I know mine are a bit of a stretch...so please share.
So far, this is what I have come up with:
1. Lines of Code (LOC) - I don't believe this is necessarily a reflection of good or bad code. For instance, I can take that 2 line INSERT statement and turn it into 20 lines.
Was
INSERT INTO my_table(id, col1, col2, col3, col4, col5, col6, col7, col8, col9 )Is
VALUES ( 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 );
INSERT INTO my_tableThat's a pretty sane example. The 2 line version isn't all that bad, but it does run off the page. The point I am trying to make is that "cleaning" up can actually add more lines to your code.
( id,
col1,
col2,
col3,
col4,
col5,
col6,
col7,
col8,
col9 )
VALUES
( 1,
2,
3,
4,
5,
6,
7,
8,
9,
10 );
In my opinion, when more than one person is going to support the code, readability is a nice thing. Whether or not you like my style, it is (more) readable. So LOC is not necessarily a great metric, but it can give you an idea which way you are going (after it has been properly formatted anyway).
2. COMMITs - Many argue that there should (almost) never be commits (an exception is logging with the AUTONOMOUS_TRANSACTION pragma) in the database. The calling application should perform the commits. Unfortunately that general rule is not always followed. I've added it to my list of metrics because it is pertinent to our environment. Of course I have gone to great pains to make sure that the removal of one commit will not impact the entire system...that possibility does exist when you have commits everywhere.
3. Text - This was a real stretch. What is the size of the individual procedure, package or function? I wouldn't have considered it (I never have until now), but I was desperate to define something...anything. How do you determine that?
SELECT name, type, SUM( LENGTH( text ) ) t
FROM dba_source
WHERE owner = 'MY_OWNER'
AND name = 'MY_NAME';
4. Dependencies - Also known, to me, as modular code. Why have 200 INSERT statements into a single table when you could wrap that up into a single procedure and call that? If you add a column, you'll still have to go through and fix all those occurences (if it's not defaulted to something). But if you remove a column from that table, it can easily be hidden from the calling code, thus you only have to change it in one place. Of course you wouldn't want to leave it there forever, but it can be done piece-meal, bit by bit as you work on affected parts.
Have you ever thought about this before? What kind of metrics would you suggest? I know mine are a bit of a stretch...so please share.
Monday, September 28, 2009
Offset Costs to OOW?
I had an idea today (yeah, I know, scary).
What if I got someone to take ORACLENERD T-Shirts to Oracle OpenWorld and sold them there, on site? It would help me by getting the word (and the t-shirt) out, and it could help you as I would split any profit with you.
Not sure if it could be done or if anyone would be willing to do it...but hey, desperate times calls for desperate measures. If you are at all interested, let me know.
What if I got someone to take ORACLENERD T-Shirts to Oracle OpenWorld and sold them there, on site? It would help me by getting the word (and the t-shirt) out, and it could help you as I would split any profit with you.
Not sure if it could be done or if anyone would be willing to do it...but hey, desperate times calls for desperate measures. If you are at all interested, let me know.
Blog Update
Somewhat spurred on by the redesign of the AppsLab last week, I decided to (finally) do a little redesign myself.
Friday night I spent about 6 hours on it.
Minus a few minor modifications, I had been using the original design I started with 2 years ago. I liked it as it was fairly simple and allowed for a lot of space for code (as opposed to the limited width blogger templates). In fact, anytime a technical friend starts one up, I suggest the use of a screen wide template because inevitably, their code examples will not look so good.
First thing I did was remove almost all of the <div>/<span> tags. I've never liked them. I prefer the old <table> tag approach. Of course I am not a web guy or designer by trade, so I probably miss out on the advantages...actually, I don't use them like they do so who cares. Apparently the differences are great amongst some in the web community, religious I would dare to say. Table tags are like putting the commas where they should go, at the end of the line. The span/div tags are like putting them in front.
That was tedious to say the least.
Also inspired by Rich's redesign of their social media buttons:

I decided to do the same. A couple of times. What's up top is what I ended up with. A brief survey on Twitter has some people not liking them. What do you think?
I like them because I made them (mostly). Of the 6 hours, probably 4 were spent in Gimp trying to create those silly things. The idea was simple, I wanted more real-estate on the side and there seemed to be a bit of unused space up top.
Tell me what you think in the comments. Good? Bad? Indifferent?
While I'm on the subject of the blog, I've been trying to reconcile the differences in numbers between the statistics that are gathered. There are three services I use: GoDaddy, their default web server statistics they provide, Google Analytics which I've been using since the beginning, and most recently, Quantcast.
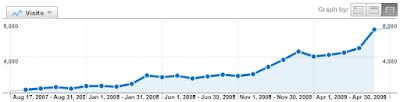
Here are the last 2 years from Google Analytics:
Here they are from the web server statistics (GoDaddy):
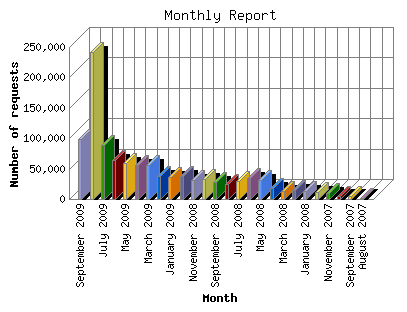
I have no idea what that large spike is...here are the numbers for the last 9 months:
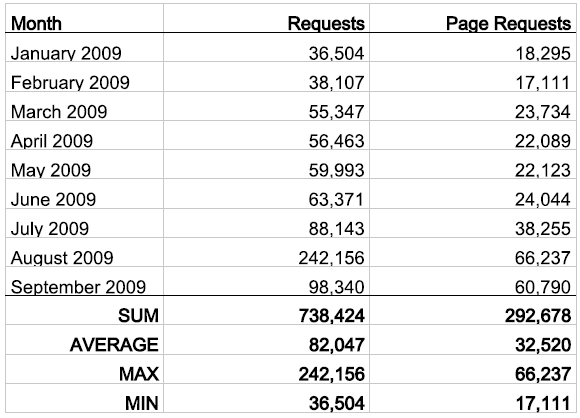
Of course there is no explanation of what is a "request" and a "page request." I'm pretty sure I've never had 242K hits. I can only assume that "request" includes all the objects that are downloaded with each page (css/images/javascript/etc). Which leaves me with page requests. Neither Analytics or Quantcast has ever shown a number in the tens of thousands (though last month did show a total of about 10k page views). Not really sure what to make of it though. I'd love to say that I'm getting 60K hits per month, but I don't believe that to be the case.
Anyway, if you know the difference let me know.
Friday night I spent about 6 hours on it.
Minus a few minor modifications, I had been using the original design I started with 2 years ago. I liked it as it was fairly simple and allowed for a lot of space for code (as opposed to the limited width blogger templates). In fact, anytime a technical friend starts one up, I suggest the use of a screen wide template because inevitably, their code examples will not look so good.
First thing I did was remove almost all of the <div>/<span> tags. I've never liked them. I prefer the old <table> tag approach. Of course I am not a web guy or designer by trade, so I probably miss out on the advantages...actually, I don't use them like they do so who cares. Apparently the differences are great amongst some in the web community, religious I would dare to say. Table tags are like putting the commas where they should go, at the end of the line. The span/div tags are like putting them in front.
That was tedious to say the least.
Also inspired by Rich's redesign of their social media buttons:
I decided to do the same. A couple of times. What's up top is what I ended up with. A brief survey on Twitter has some people not liking them. What do you think?
I like them because I made them (mostly). Of the 6 hours, probably 4 were spent in Gimp trying to create those silly things. The idea was simple, I wanted more real-estate on the side and there seemed to be a bit of unused space up top.
Tell me what you think in the comments. Good? Bad? Indifferent?
While I'm on the subject of the blog, I've been trying to reconcile the differences in numbers between the statistics that are gathered. There are three services I use: GoDaddy, their default web server statistics they provide, Google Analytics which I've been using since the beginning, and most recently, Quantcast.
Here are the last 2 years from Google Analytics:
Here they are from the web server statistics (GoDaddy):
I have no idea what that large spike is...here are the numbers for the last 9 months:
Of course there is no explanation of what is a "request" and a "page request." I'm pretty sure I've never had 242K hits. I can only assume that "request" includes all the objects that are downloaded with each page (css/images/javascript/etc). Which leaves me with page requests. Neither Analytics or Quantcast has ever shown a number in the tens of thousands (though last month did show a total of about 10k page views). Not really sure what to make of it though. I'd love to say that I'm getting 60K hits per month, but I don't believe that to be the case.
Anyway, if you know the difference let me know.
Friday, September 25, 2009
"Shrink" UNDO Tablespace
Having completely screwed up my sandbox database, I decided to do a little house cleaning. Yes, I know, I would probably break something. But I have backups now.
Specifically, I wanted to reclaim some space. More specifically, I didn't like the UNDO data file being 6GB. Completely unnecessary.
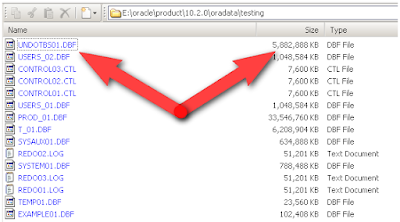
So I found this thread on how to "shrink" it.
1. Create a new temporary UNDO tablespace.
2. Point your database to the new UNDO tablespace.
3. Drop the original UNDO tablespace.
Optional
4. Create new UNDO tablespace matching the original.
5. Point your database to the old new UNDO tablespace.
6. Drop the new old UNDO tablespace.
7. Remove the old files from the filesystem
Just a reminder, this is a sandbox used for testing, not a production database.
Specifically, I wanted to reclaim some space. More specifically, I didn't like the UNDO data file being 6GB. Completely unnecessary.
So I found this thread on how to "shrink" it.
1. Create a new temporary UNDO tablespace.
2. Point your database to the new UNDO tablespace.
3. Drop the original UNDO tablespace.
Optional
4. Create new UNDO tablespace matching the original.
5. Point your database to the old new UNDO tablespace.
6. Drop the new old UNDO tablespace.
7. Remove the old files from the filesystem
--STEP 1And then you can remove the old datafiles.
CREATE UNDO TABLESPACE undotbs2 DATAFILE 'UNDOTBS_02.DBF'
SIZE 1G
AUTOEXTEND ON;
--STEP 2
ALTER SYSTEM SET UNDO_TABLESPACE = undotbs2;
--STEP 3
DROP TABLESPACE undotbs INCLUDING CONTENTS;
--STEP 4
CREATE TABLESPACE undotbs DATAFILE 'UNDOTBS_01.DBF'
SIZE 1G
AUTOEXTEND ON;
--STEP 5
ALTER SYSTEM SET UNDO_TABLESPACE = undotbs;
--STEP 6
DROP TABLESPACE undotbs2 INCLUDING CONTENTS;
Just a reminder, this is a sandbox used for testing, not a production database.
Thursday, September 24, 2009
Random Things: Volume #9
Who's worked with a female developer?
I wish there were more women in our field. My team is currently made up of 4 women and 2 men. How cool is that? I even once worked with Doctor Colonel Irina Spalko...or was it Colonel Doctor? Eh...who cares?
OpenWorld
Just a little over 2 weeks away...I hope you're ready. With the announcement of Exadata 2 and 11gR2 in the past month; SQL Developer today...what will they unveil at OpenWorld? It has to be big right?
There are still ways to get a free pass if you are so inclined. A week ago, the Oracle OpenWorld blog announced that they were accepting Video entries:
SQL Developer: 2.1 Early Adopter 1
A new, early adopter release has been...umm...released.
How to Scare-off Female Candidates (from Josh Perry)Friends and I joke about this all the time. Working in IT, we tend to notice women, especially those in our profession, a lot more. Why? Because we're dorks/geeks/nerds?
At a company I once worked at, several of the developers would cycle into work each day. It was an exercise/eco-friendly thing, I guess. One of the more hard-core cyclists would often wear a full-body Lycra cycling suit for his ride... and would usually not bother changing out of it. He'd just hang out all day, wearing his spandex suit, and writing his code. Being a heavily male-dominated office (like most in the IT world), he could get away with this.
When it came to hiring a new developer, we found that rarest of gems: a qualified female candidate. Being female, she was pretty much guaranteed a job offer as soon as she sent in her résumé, but they brought her in for an interview just in case.
While she was in the interview, one of the interviewers casually joked, "so, how do you feel about working with men wearing full-body spandex suits?"
An uncomfortable silence ensued. They offered her the job. She declined.
The Daily WTF

I wish there were more women in our field. My team is currently made up of 4 women and 2 men. How cool is that? I even once worked with Doctor Colonel Irina Spalko...or was it Colonel Doctor? Eh...who cares?
OpenWorld
Just a little over 2 weeks away...I hope you're ready. With the announcement of Exadata 2 and 11gR2 in the past month; SQL Developer today...what will they unveil at OpenWorld? It has to be big right?
There are still ways to get a free pass if you are so inclined. A week ago, the Oracle OpenWorld blog announced that they were accepting Video entries:
We're starting a video challenge on the blog today where every entry will receive the same registration discount that was open during the Early Bird registration period.OK, maybe it's not completely free...but it's better than paying full price.
Just make a 30-second video describing why you want to go to Oracle OpenWorld 2009.Use any camera you have close at hand—Webcam, cell phone, handheld. Give us your best, most creative, most innovative pitch, and post your video as a response to ours above on the Oracle Web Video YouTube channel before September 30.
SQL Developer: 2.1 Early Adopter 1
A new, early adopter release has been...umm...released.
SQL Developer: 2.1 Early Adopter 1 (2.1.0.62.61)
Reason #23 to use Twitter, beat the press.
Let's check out the feed for Oracle Press Releases:
Nope, nothing there.
On twitter though, you have the (in)famous Kris Rice, Product Manager or something in charge of SQL Developer.
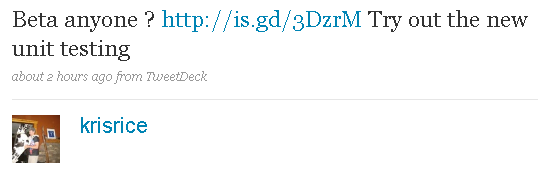
Check out the Feature List.
Download it here.
Probably the biggest surprise, to me anyway, was the inclusion of a unit testing framework. Haven't had a chance to check it out yet but you can find a tutorial here.
Let's check out the feed for Oracle Press Releases:
Nope, nothing there.
On twitter though, you have the (in)famous Kris Rice, Product Manager or something in charge of SQL Developer.
Check out the Feature List.
Download it here.
Probably the biggest surprise, to me anyway, was the inclusion of a unit testing framework. Haven't had a chance to check it out yet but you can find a tutorial here.
Wednesday, September 23, 2009
Testing: FLASHBACK, Data Pump and RMAN
I've been having loads of fun the last few days, Learning By Breaking, Learning By...Breaking?, IMPDP and REMAP_TABLESPACE and finally How To: Clean Your Schema (which needs a little work).
All of this in an effort to test my migration script with changes in the hundreds. A quick recap:
1. Import metadata from production environment from 4 schemas. This includes mapping all the tablespaces from production to USER in my sandbox.
2. Create restore point.
3. Run build script.
4. Check for errors, fix errors
5. Flashback database to pre-deployment state.
6. Rinse and repeat as necessary.
If you have read any of those other posts, you'll know that:
a. I'm an idiot.
b. I like to guess.
3. I performed my first "recovery."
d. I learned the basics of Data Pump.
e. I like to break things.
For #1 above, import metadata, I've learned some hard lessons. I've had to repeat this step a number of times because I've either corrupted my database or dropped the restore point before flashing back.
And just now, a colleague of mine helped me out with another problem. See, the import process was extremely slow. Part of the reason (I think) I corrupted the silly thing was because I was mucking around at a level I don't quite understand...storage.
I just sent this pic to him:
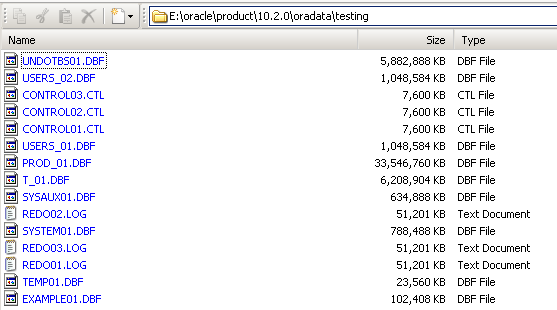
I was like, "WTF? Why do I need a 33GB datafile for metadata?"
Him: "Ummm...idiot...it preallocates the space which is based on production."
Me: <crickets>
Me: "How can I change the storage characteristics?" (I sent him the link to the Data Pump docs.)
Me: "How about this?" (Link to the TRANSFORM clause)
Aha...TRANSFORM has 4 options:
1. SEGMENT_ATTRIBUTES (Y, Default, to keep them, N to toss 'em)
2. STORAGE (Y, Default, to keep them, N to toss them)
3. OID
4. PCTSPACE
Where does RMAN fit into all of this? I'm not really sure. Last night I issued
One of these days I'll get around to virtualizing all of this. I imagine that has to be easier, import the data, take a snapshot, run the script, fix, revert to previous snapshot. If I did that though, I wouldn't get to play (learn) with all of these cool tools.
All of this in an effort to test my migration script with changes in the hundreds. A quick recap:
1. Import metadata from production environment from 4 schemas. This includes mapping all the tablespaces from production to USER in my sandbox.
2. Create restore point.
3. Run build script.
4. Check for errors, fix errors
5. Flashback database to pre-deployment state.
6. Rinse and repeat as necessary.
If you have read any of those other posts, you'll know that:
a. I'm an idiot.
b. I like to guess.
3. I performed my first "recovery."
d. I learned the basics of Data Pump.
e. I like to break things.
For #1 above, import metadata, I've learned some hard lessons. I've had to repeat this step a number of times because I've either corrupted my database or dropped the restore point before flashing back.
And just now, a colleague of mine helped me out with another problem. See, the import process was extremely slow. Part of the reason (I think) I corrupted the silly thing was because I was mucking around at a level I don't quite understand...storage.
I just sent this pic to him:
I was like, "WTF? Why do I need a 33GB datafile for metadata?"
Him: "Ummm...idiot...it preallocates the space which is based on production."
Me: <crickets>
Me: "How can I change the storage characteristics?" (I sent him the link to the Data Pump docs.)
Me: "How about this?" (Link to the TRANSFORM clause)
Aha...TRANSFORM has 4 options:
1. SEGMENT_ATTRIBUTES (Y, Default, to keep them, N to toss 'em)
2. STORAGE (Y, Default, to keep them, N to toss them)
3. OID
4. PCTSPACE
Where does RMAN fit into all of this? I'm not really sure. Last night I issued
RECOVER DATABASE;and it worked perfectly. Now, once I get an import completed, I take a backup of the tablespace. (I've since created a separate tablespace for the 2 largest schemas being imported.) That way, if I drop the restore point before flashing back, I should be able to restore it back to it's original state.
One of these days I'll get around to virtualizing all of this. I imagine that has to be easier, import the data, take a snapshot, run the script, fix, revert to previous snapshot. If I did that though, I wouldn't get to play (learn) with all of these cool tools.
Tuesday, September 22, 2009
Learning By...Breaking?
I caught Chen Gwen mocking me the other day on Twitter.

That was in response to Learning By Breaking.
Come on. Give me a break.
Now if I were a big DBA (not a little dba), I would not be so haphazard in my approach. This is a sandbox after all.
Naturally, I was at it again today.
I performed my very first recovery today. That is if you consider
Just a reminder as to what I am doing. I am testing my migration script (a couple of hundred DDL/DML and code changes) in an object only copy of production in my own private idaho...sandbox. I run the script, find the errors (usually order of execution related), fix the script(s), flashback the database and then rerun. To make my life someone easier, I created a script that performs the necessary commands to flashback the database.
Somewhere along the way I believe I have managed to destroy my database. How did I do that? Well, I don't know. I do know I have accidentally dropped the restore point (2 times) prior to flashing back. When that happens, I clean up the database with one of 2 methods:
1. Use my handy-dandy clean up script to remove all the objects
2. DROP USER test CASCADE;
That's followed by a full import (via datapump) of the 2 necessary schemas.
So tonight I went to flashback and...well, something went really wrong. Something about I needed to recover the system datafile (I didn't save that one unfortunately).
Meanwhile, back in SQL*Plus I keep trying different commands.
Did I get it?
Lo and behold it worked. I was able to get back into my precious sandbox.
What's the moral of the story? I have no idea. Like I said last time, I learned something...I just don't know what it is yet.
Wait, I did learn one thing...Oracle is a pretty incredible piece of software if the likes of me can go in, muck it up, and it still comes back to life. That my friends, is pretty impressive.
That was in response to Learning By Breaking.
Come on. Give me a break.
Now if I were a big DBA (not a little dba), I would not be so haphazard in my approach. This is a sandbox after all.
Naturally, I was at it again today.
I performed my very first recovery today. That is if you consider
ALTER DATABASE RECOVER;a recovery. To make it worse, I guessed at the syntax.
Just a reminder as to what I am doing. I am testing my migration script (a couple of hundred DDL/DML and code changes) in an object only copy of production in my own private idaho...sandbox. I run the script, find the errors (usually order of execution related), fix the script(s), flashback the database and then rerun. To make my life someone easier, I created a script that performs the necessary commands to flashback the database.
ALTER DATABASE CLOSE;Then I just run @flashback after disconnecting from my other session.
FLASHBACK DATABASE TO RESTORE POINT PRE_DEPLOY;
SHUTDOWN;
STARTUP;
ALTER DATABASE OPEN RESETLOGS;
Somewhere along the way I believe I have managed to destroy my database. How did I do that? Well, I don't know. I do know I have accidentally dropped the restore point (2 times) prior to flashing back. When that happens, I clean up the database with one of 2 methods:
1. Use my handy-dandy clean up script to remove all the objects
2. DROP USER test CASCADE;
That's followed by a full import (via datapump) of the 2 necessary schemas.
So tonight I went to flashback and...well, something went really wrong. Something about I needed to recover the system datafile (I didn't save that one unfortunately).
ALTER DATABASE RECOVER?Nope.
ERROR at line 1:Sweet...Oracle's giving me a suggestion. What does that mean? (Me guessing again):
ORA-00279: change 9235581 generated at 09/22/2009 21:24:09 needed for thread 1
ORA-00289: suggestion : FRA\TESTING\ARCHIVELOG\2009_09_22\O1_MF_1_23_%U_.ARC
ORA-00280: change 9235581 for thread 1 is in sequence #23
ALTER DATABASE RECOVER ARCHIVELOG 'FRA\TESTING\ARCHIVELOG\2009_09_22\O1_MF_1_23_%U_.arcThat second one looked closer right? Meanwhile, I began a backup of the archived redo logs.
*
ERROR at line 1:
ORA-00905: missing keyword
ALTER DATABASE RECOVER LOGFILE 'FRA\TESTING\ARCHIVELOG\2009_09_22\O1_MF_1_23_%U_.ARC
'
*
ERROR at line 1:
ORA-00308: cannot open archived log 'FRA\TESTING\ARCHIVELOG\2009_09_22\O1_MF_1_23_%U
_.ARC'
ORA-27041: unable to open file
OSD-04002: unable to open file
O/S-Error: (OS 2) The system cannot find the file specified.
BACKUP ARCHIVELOGS ALL;I wasn't really sure what that was going to do, but I needed some space.
Meanwhile, back in SQL*Plus I keep trying different commands.
SQL>ALTER DATABASE RECOVER TABLESPACE SYSTEM;I'm pretty sure I picked those up in a Google search (in other words, I didn't bother to click through). Out of frustration, I killed the instance (net stop oracleservicetesting) and tried to bring it back up.
ALTER DATABASE RECOVER TABLESPACE SYSTEM
*
ERROR at line 1:
ORA-00275: media recovery has already been started
SQL>ALTER DATABASE RECOVER TABLESPACE USERS;
ALTER DATABASE RECOVER TABLESPACE USERS
*
ERROR at line 1:
ORA-00275: media recovery has already been started
SQL>ALTER DATABASE RECOVER;
ALTER DATABASE RECOVER
*
ERROR at line 1:
ORA-00275: media recovery has already been started
SQL>ALTER DATABASE OPEN;
ALTER DATABASE OPEN
*
ERROR at line 1:
ORA-01156: recovery in progress may need access to files
STARTUP MOUNT;For some unknown reason, I went back into RMAN (the session I didn't save to cut and paste) and issued
SQL>RECOVER DATAFILE 'E:\ORACLE\PRODUCT\10.2.0\ORADATA\TESTING\SYSTEM01.DBF';
ORA-00283: recovery session canceled due to errors
ORA-38798: Cannot perform partial database recovery
ORA-38797: Full database recovery required after a database has been flashed back
RECOVER DATABASE;It's doing something...
Did I get it?
Lo and behold it worked. I was able to get back into my precious sandbox.
What's the moral of the story? I have no idea. Like I said last time, I learned something...I just don't know what it is yet.
Wait, I did learn one thing...Oracle is a pretty incredible piece of software if the likes of me can go in, muck it up, and it still comes back to life. That my friends, is pretty impressive.
T-Shirt: MONITOR RANDOM SQL OUTPUT
For all those not in the US or Canada that have expressed interest in the T-Shirts, I'm looking for other distributors...specifically in Europe and India. The cost to ship to these locales is prohibitively expensive (I'm sorry for that). Hopefully I'll have an answer to this fairly soon.


Monday, September 21, 2009
Learning By Breaking
I've spent the last couple of days building and rebuilding my sandbox database.
I can't get it just right.
Last night while running my scripts, none of the foreign key clauses would work. Primary key doesn't exist? WTF?
Do a quick check on the count of indexes...it's about 10% of what it should have been.
Oh yeah, when using REMAP_TABLESPACE, it helps to include the index tablespaces as well. $#*@~!
So I queried all the index tablespaces and put them into my parameter file for impdp.
Only to have my database freeze about 70% of the time. Being just a dba and not a DBA, I figured I'd just add a datafile. OK, so the first time I created it is was 1GB. I didn't bother to resize it.
Then it hung up again. (Of course I'm not bothering to find the root cause of the issue, I'm just brute forcing it). Somewhere in the index creation (reading from the console output anyway).
Killed it again.
Cleaned out the schema again.
Rinse and repeat a couple more times.
Then I decided to drop a datafile, the small one I created up above. Yes, I could have resized it...but I'm just a rookie. Used the OFFLINE DROP, shutdown the database and deleted the datafile.
Reran the impdp.
OK, let's drop the tablespace and try again.
So I dropped all the users (just a reminder, this is just a sandbox) and tried it again.
For whatever reason, I'm a glutton for punishment. I don't like the look of "USERS2" so I want to go back to "USERS." Let's go through this again.
Obviously no one should let me do this sort of thing anywhere near a production database. I know just enough to be really, really dangerous. It is find having to go through this (painful) exercise once in awhile in a closed environment. Helps to understand a little bit about how the database works. I'm not sure what exactly I did learn, other than I am a moron...but it was...fun.
I can't get it just right.
Last night while running my scripts, none of the foreign key clauses would work. Primary key doesn't exist? WTF?
Do a quick check on the count of indexes...it's about 10% of what it should have been.
Oh yeah, when using REMAP_TABLESPACE, it helps to include the index tablespaces as well. $#*@~!
So I queried all the index tablespaces and put them into my parameter file for impdp.
Only to have my database freeze about 70% of the time. Being just a dba and not a DBA, I figured I'd just add a datafile. OK, so the first time I created it is was 1GB. I didn't bother to resize it.
Then it hung up again. (Of course I'm not bothering to find the root cause of the issue, I'm just brute forcing it). Somewhere in the index creation (reading from the console output anyway).
Killed it again.
Cleaned out the schema again.
Rinse and repeat a couple more times.
Then I decided to drop a datafile, the small one I created up above. Yes, I could have resized it...but I'm just a rookie. Used the OFFLINE DROP, shutdown the database and deleted the datafile.
Reran the impdp.
Connected to: Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - ProductionOops.
With the Partitioning, OLAP and Data Mining options
ORA-39001: invalid argument value
ORA-00376: file 6 cannot be read at this time
ORA-01110: data file 6: 'USERS02.DBF'
OK, let's drop the tablespace and try again.
DROP TABLESPACE users INCLUDING CONTENTS;OK, let's create a new tablespace
ERROR at line 1:
ORA-12919: Can not drop the default permanent tablespace
CREATE TABLESPACE USERS2 DATAFILE 'USERS2_01.DBF' SIZE 10G AUTOEXTEND ON;Now I'll make that one the default
ALTER DATABASE DEFAULT TABLESPACE USERS2;Now I'll drop the USERS tablespace
DROP TABLESPACE users INCLUDING CONTENTS;Killing me...
ERROR at line 1:
ORA-22868: table with LOBs contains segments in different tablespaces
So I dropped all the users (just a reminder, this is just a sandbox) and tried it again.
SYS@TESTING>DROP TABLESPACE users INCLUDING CONTENTS;Finally!
Tablespace dropped.
For whatever reason, I'm a glutton for punishment. I don't like the look of "USERS2" so I want to go back to "USERS." Let's go through this again.
ALTER DATABASE DEFAULT TABLESPACE USERS;Add a second datafile just for fun:
Database altered.
DROP TABLESPACE users2 INCLUDING CONTENTS;
Tablespace dropped.
ALTER TABLESPACE USERS ADD DATAFILE 'USERS_02.DBF' SIZE 10G AUTOEXTEND ON;Done.
Obviously no one should let me do this sort of thing anywhere near a production database. I know just enough to be really, really dangerous. It is find having to go through this (painful) exercise once in awhile in a closed environment. Helps to understand a little bit about how the database works. I'm not sure what exactly I did learn, other than I am a moron...but it was...fun.
Saturday, September 19, 2009


Thursday, September 17, 2009
T-Shirt: Constraints
Just in case you ever forget what the 5 constraints in an Oracle database are...


SQL: Calculate Wasted Time
Inspired by this today:

I answered with this:

I started to do it in SQL, but then I got impatient. I finished it in Excel just to get it done. Some time later, I decided to do it in SQL...just because it's fairly easy.
I know there are better/different ways to do it, so share please.
I answered with this:
I started to do it in SQL, but then I got impatient. I finished it in Excel just to get it done. Some time later, I decided to do it in SQL...just because it's fairly easy.
I know there are better/different ways to do it, so share please.
Those minutes are precious...so don't waste them.
SELECT
ROUND( d * 10 * 14 * sal_per_minute, 2 ) yearly_cost,
ROUND( ( d / 4 ) * 10 * 14 * sal_per_minute, 2 ) quarterly_cost,
ROUND( ( d / 12 ) * 10 * 14 * sal_per_minute, 2 ) monthly_cost,
ROUND( 5 * 10 * 14 * sal_per_minute, 2 ) weekly_cost,
ROUND( 10 * 14 * sal_per_minute, 2 ) daily_cost
FROM
(
SELECT
COUNT( CASE
WHEN TO_CHAR( s, 'D' ) NOT IN ( 1, 7 )
THEN 1
ELSE NULL
END ) - 10 d,
MAX( sal ) sal_per_minute
FROM
(
SELECT
TO_DATE( '31-DEC-2008', 'DD-MON-YYYY' ) + rownum s,
( 100000 / 2080 ) / 60 sal
FROM dual
CONNECT BY LEVEL <= 365
)
);
YEARLY_COST QUARTERLY_COST MONTHLY_COST WEEKLY_COST DAILY_COST
----------- -------------- ------------ ----------- ----------
28157.05 7039.26 2346.42 560.9 112.18
How To: Clean Your Schema
I'm going to be testing my migration script in my personal sandbox. I just want to make sure I have the exact order of execution for all the objects before sending it on to the DBA.
In that regard, I had to clean up my existing schemas. By "clean up" I mean remove all of the objects. Laurent Schneider posted something very similar last year, but it didn't handle scheduling objects (there is a reference to scheduled jobs in the comments though).
So here's my version which handles TYPES, JOBS (Scheduler), PROGRAMs, CHAINs and TABLEs. There are probably more cases that I did not catch, but this is the most I have come across so far.
In that regard, I had to clean up my existing schemas. By "clean up" I mean remove all of the objects. Laurent Schneider posted something very similar last year, but it didn't handle scheduling objects (there is a reference to scheduled jobs in the comments though).
So here's my version which handles TYPES, JOBS (Scheduler), PROGRAMs, CHAINs and TABLEs. There are probably more cases that I did not catch, but this is the most I have come across so far.
DECLAREEnjoy.
l_string VARCHAR2(4000);
l_execute BOOLEAN := TRUE;
BEGIN
FOR i IN ( SELECT DISTINCT
owner,
( CASE
WHEN object_type = 'PACKAGE BODY' THEN 'PACKAGE'
ELSE object_type
END ) object_type,
object_name
FROM dba_objects
WHERE owner IN ( 'MY_SCHEMA' )
AND object_type IN ( 'SEQUENCE', 'VIEW', 'SYNONYM',
'PROCEDURE', 'FUNCTION', 'PACKAGE',
'JAVA SOURCE', 'JAVA CLASS', 'TYPE',
'JOB', 'SCHEDULE', 'PROGRAM',
'JAVA RESOURCE', 'CHAIN', 'TABLE' )
ORDER BY owner, object_name )
LOOP
l_string := 'DROP ';
l_string := i.object_type || ' ';
l_string := i.owner || '."';
l_string := i.object_name || '"';
CASE
WHEN i.object_type = 'TABLE' THEN
l_string := l_string || ' CASCADE CONSTRAINTS';
WHEN i.object_type = 'TYPE' THEN
l_string := l_string || ' FORCE';
WHEN i.object_type = 'JOB' THEN
l_execute := FALSE;
dbms_scheduler.drop_job
( job_name => i.owner || '."' || i.object_name || '"',
force => TRUE );
WHEN i.object_type = 'SCHEDULE' THEN
l_execute := FALSE;
dbms_scheduler.drop_schedule
( schedule_name => i.owner || '."' || i.object_name || '"',
force => TRUE );
WHEN i.object_type = 'PROGRAM' THEN
l_execute := FALSE;
dbms_scheduler.drop_program
( program_name => i.owner || '."' || i.object_name || '"',
force => TRUE );
WHEN i.object_type = 'CHAIN' THEN
l_execute := FALSE;
dbms_scheduler.drop_chain
( chain_name => i.owner || '."' || i.object_name || '"',
force => TRUE );
ELSE
NULL;
END CASE;
IF l_execute THEN
EXECUTE IMMEDIATE l_string;
ELSE
l_execute := TRUE;
END IF;
END LOOP;
END;
/
Wednesday, September 16, 2009
T-Shirt: DBA
I've got a million of 'em!

For the professional DBA. Subtle and understated. (I'm trying to work on good marketing copy too.)

For the professional DBA. Subtle and understated. (I'm trying to work on good marketing copy too.)
The Database Cleanup
I found a recent discussion on Ask Tom about "Unused Objects" via David Aldridge's post, Metacode Gone Wrong. The original poster's question:
At my last gig, I went about an effort to clean up the database. We had close to 600 tables in a single schema. The one good thing (for me anyway), what that those tables were not accessible outside of the database, they were called through PL/SQL. Finding dependencies (DBA_DEPENDENCIES) was fairly easy...but I also ran across the caveat that he mentions, Dynamic SQL. Nothing strikes fear in you quicker than the realization that all of your work might be nullified because you didn't consider the use [Dynamic SQL] up front.
I would complain during code review/architectural sessions about the use of Dynamic SQL...not sure if it was listened, but I got my opinion in.
Documentation of a database, in my recent experience anyway, is the last thing on anyone's mind. It's seen as time-consuming and un-important. I like what David says in the Ask Tom comments:
Since I've had so much experience at this of late, I'll list the steps I have taken in the hopes that you can find something useful yourself.
1. DBA_DEPENDENCIES - It's a great place to start, but it's not a panacea. You can get 90% of everything you need here. It's that last 10% that is the hardest. For example, I'll focus in on one table, query DBA_DEPENDENCIES, and then put that list into a spreadsheet where I can then track my progress. Usually I'll add "fixed", "fixed date" and "comments" columns so I'll know that I have addressed it. I'll typically have a worksheet for each table.
2. Privileges - Specifically in relation to tables. Do other database users have DML access? SELECT is one thing (still important) but INSERT/UPDATE/DELETE is entirely different. If other users do have access, are they service accounts (used by outside applications) or are they solely database users (another application)?
3. Auditing - I had never thought to use auditing for this purpose, but it might be helpful in the future.
4. Logging - If you suspect a piece of code is no longer used (naturally there is no documentation), but are not sure, you can add a bit of logging code to it. It's not the best method in the world, but it works. With all things, it's not a 100% guarantee either, the code may be called once a year, there is really no way to tell.
5. Thorough and Meticulous Analysis - This isn't really a method but it's going in here anyway. Document everything you can which includes everything you've done. At the very least, you'll have some documentation to show for it. At the very least, you'll have a much better understanding of your application and it's inner-workings.
Update 09/17/2009 12:30 PM
Dom Brooks reminded me of DBA_SOURCE in the comments so I'm adding that in.
6. DBA_SOURCE - A case-insensitive search of DBA_SOURCE is a must have as well. Allows you to find all the references to a table/procedure/etc. Some may have just be in comments, but some may also be contained in Dynamic SQL.
We are in a process of removing unused objects (tables/functions/procedures/packages) from the database. Is there any script(suggestions) or short-cut method to find these unused objects (tables/functions/procedures/packages not used in ddl/dml/select statements for more than 3 months).To which Tom replied:
There are more than 500 objects(tables/functions/procedures/packages) in our database.
At least PLEASE help me in finding unused TABLES.For other objects I'm thinking to check manually in the application code(using find and grep commands)
Please Help me.
You'll have to enable auditing and then come back in 3 months to see.I've been in several environments where production was not documented very well (if at all). I guess that's fortunate for me, as there is always work to be done.
We don't track this information by default -- also, even with auditing, it may be very possible to have an object that is INDIRECTLY accessed (eg: via a foreign key for example) that won't show up.
You can try USER_DEPENDENCIES but that won't tell you about objects referenced by code in
client apps or via dynamic sql
I'm always perplexed by this. How does one get into a production environment where by
they don't know what the objects are used by/for? No documentation or anything?
At my last gig, I went about an effort to clean up the database. We had close to 600 tables in a single schema. The one good thing (for me anyway), what that those tables were not accessible outside of the database, they were called through PL/SQL. Finding dependencies (DBA_DEPENDENCIES) was fairly easy...but I also ran across the caveat that he mentions, Dynamic SQL. Nothing strikes fear in you quicker than the realization that all of your work might be nullified because you didn't consider the use [Dynamic SQL] up front.
I would complain during code review/architectural sessions about the use of Dynamic SQL...not sure if it was listened, but I got my opinion in.
Documentation of a database, in my recent experience anyway, is the last thing on anyone's mind. It's seen as time-consuming and un-important. I like what David says in the Ask Tom comments:
I think that if documenting code makes people sad then they ought to be in their bedroom writing card games in VB. The sad thing is that it doesn't have to be a huge overhead, it just has to be well thoughtout and #actually done#.How To Clean Up The Database
Since I've had so much experience at this of late, I'll list the steps I have taken in the hopes that you can find something useful yourself.
1. DBA_DEPENDENCIES - It's a great place to start, but it's not a panacea. You can get 90% of everything you need here. It's that last 10% that is the hardest. For example, I'll focus in on one table, query DBA_DEPENDENCIES, and then put that list into a spreadsheet where I can then track my progress. Usually I'll add "fixed", "fixed date" and "comments" columns so I'll know that I have addressed it. I'll typically have a worksheet for each table.
2. Privileges - Specifically in relation to tables. Do other database users have DML access? SELECT is one thing (still important) but INSERT/UPDATE/DELETE is entirely different. If other users do have access, are they service accounts (used by outside applications) or are they solely database users (another application)?
3. Auditing - I had never thought to use auditing for this purpose, but it might be helpful in the future.
4. Logging - If you suspect a piece of code is no longer used (naturally there is no documentation), but are not sure, you can add a bit of logging code to it. It's not the best method in the world, but it works. With all things, it's not a 100% guarantee either, the code may be called once a year, there is really no way to tell.
5. Thorough and Meticulous Analysis - This isn't really a method but it's going in here anyway. Document everything you can which includes everything you've done. At the very least, you'll have some documentation to show for it. At the very least, you'll have a much better understanding of your application and it's inner-workings.
Update 09/17/2009 12:30 PM
Dom Brooks reminded me of DBA_SOURCE in the comments so I'm adding that in.
6. DBA_SOURCE - A case-insensitive search of DBA_SOURCE is a must have as well. Allows you to find all the references to a table/procedure/etc. Some may have just be in comments, but some may also be contained in Dynamic SQL.


Tuesday, September 15, 2009
PL/SQL: Exceptions
I'm not really sure what I learned today, yet. Here's what I went through though.
I'm rebuilding/redesigning/refactoring a payment processing platform. It's complete with WHEN others...there is logging after the WHEN others, but no RAISE.
I was taught to use exceptions, which to me, meant using
Exceptions were used in the code, they were slightly different though, just the
As I peel away the layers though, far too many errors are being caught with OTHERS. Bad. Bad. Bad.
Payment processing, being at the center of most everything, should, ney, must, blow up loudly if something unknown goes wrong. Before that ever goes live you should know about the vast majority of exceptions. Vast Majority to me means 99.9%.
By blowing up loudly, you don't have to rely on looking through error logs and you are far less likely to encounter strange behavior. If one pops up that you didn't account for, it's a quick code change to add that handling.
Of course much of this is predicated on having unit tests or other testing means available. Once of the first things I did was build about 80 test cases with SQLUnit. So I am fairly confident when I make changes that I haven't affected (much) the underlying code.
Finally, on to the exceptions.
There were 4 or 5 generic exceptions (other than OTHERS) defined. I wanted more though. So I began adding them in. Currently the code travels through about 5 levels of the candy cane forest, I mean, PL/SQL. In the lower most level, I used
Rerun the tests and I can see the call stack with a reference to ORA-20001. I'm getting somewhere. That's when I realized that even if you throw an exception in that manner, if you have an exception block in the same block of code and a WHEN others, WHEN others will catch it. For some reason, I always thought it bypassed that current block of code, but then again, I've rarely used WHEN others.
One by one I began to remove the WHEN others from the calling layers. I created global exceptions:
I rerun the tests and the error propogates all the way to the top (as it should, I just wasn't used to it). Tests begin to work again and I'm all set to go. Win!
For more on exception handling in PL/SQL, go here for 10gR2, here for 11gR1, and here for 11gR2.
I'm rebuilding/redesigning/refactoring a payment processing platform. It's complete with WHEN others...there is logging after the WHEN others, but no RAISE.
I was taught to use exceptions, which to me, meant using
raise_application_error( -20001, 'something went wrong' )which meant that my calling PL/SQL had to use the PRAGMA EXCEPTION_INIT declaration. Not a big deal when it's 1 or 2 layers deep, but that's part of today's lesson (for me).
Exceptions were used in the code, they were slightly different though, just the
DECLAREvariety. It's way better than nothing and I believe they were headed in the right direction.
some_exception EXCEPTION;
BEGIN
...
As I peel away the layers though, far too many errors are being caught with OTHERS. Bad. Bad. Bad.
Payment processing, being at the center of most everything, should, ney, must, blow up loudly if something unknown goes wrong. Before that ever goes live you should know about the vast majority of exceptions. Vast Majority to me means 99.9%.
By blowing up loudly, you don't have to rely on looking through error logs and you are far less likely to encounter strange behavior. If one pops up that you didn't account for, it's a quick code change to add that handling.
Of course much of this is predicated on having unit tests or other testing means available. Once of the first things I did was build about 80 test cases with SQLUnit. So I am fairly confident when I make changes that I haven't affected (much) the underlying code.
Finally, on to the exceptions.
There were 4 or 5 generic exceptions (other than OTHERS) defined. I wanted more though. So I began adding them in. Currently the code travels through about 5 levels of the candy cane forest, I mean, PL/SQL. In the lower most level, I used
raise_application_error( -20001, 'invalid card number (gateway)' );Reran the tests and nothing showed up. I added an internal function to capture the error stack.
FUNCTION error_stack RETURN VARCHAR2so I wouldn't have to rewrite those 3 (long) lines over and over. I realize that you get an extra line in there, but I'll know to ignore it.
IS
l_error_stack VARCHAR2(32767);
BEGIN
l_error_stack := dbms_utility.format_call_stack;
l_error_stack := l_error_stack || dbms_utility.format_error_backtrace;
l_error_stack := l_error_stack || dbms_utility.format_error_stack;
RETURN l_error_stack;
END error_stack;
Rerun the tests and I can see the call stack with a reference to ORA-20001. I'm getting somewhere. That's when I realized that even if you throw an exception in that manner, if you have an exception block in the same block of code and a WHEN others, WHEN others will catch it. For some reason, I always thought it bypassed that current block of code, but then again, I've rarely used WHEN others.
One by one I began to remove the WHEN others from the calling layers. I created global exceptions:
invalid_card EXCEPTION;, removed WHEN others and created a new exception block in the top-most procedure. Perfect!
PRAGMA EXCEPTION_INIT( invalid_card, -20001 );
I rerun the tests and the error propogates all the way to the top (as it should, I just wasn't used to it). Tests begin to work again and I'm all set to go. Win!
For more on exception handling in PL/SQL, go here for 10gR2, here for 11gR1, and here for 11gR2.
Monday, September 14, 2009
Oracle + MySQL = Monopoly?
BRUSSELS -- The European Commission opened an antitrust investigation into Oracle Corp.'s $7.4 billion acquisition of Sun Microsystems Inc., dealing a blow to Oracle's efforts to keep Sun customers who are increasingly being wooed by rival technology companies.That's from EU to Probe Oracle-Sun Deal on September 3rd.
Ostensibly, this is about MySQL.
In announcing the probe, the European Union's executive arm cited concern that the deal would stymie competition for database software...Sun makes a low-cost alternative [MySQL] that is increasing in popularity.With all of the database offerings out there, how can this even be a consideration?
Let's say Oracle decides to squash MySQL (which I doubt), are you telling me that it can't or won't be forked? Are you also telling me that these businesses have no other choices in database software?
monopoly ((economics) a market in which there are many buyers but only one seller) "a monopoly on silver"; "when you have a monopoly you can ask any price you like"The wikipedia entry is littered with words like "exclusive" and phrases like "sole control." Where is the monopoly?
This isn't about Oracle, specifically, either. I could never understand the charges against Microsoft. Shouldn't they be allowed to build their systems the way they want to?
Oracle Has Customers Over a Barrell
If Oracle buys Sun, it could cripple or kill the rival product. "The Commission has an obligation to ensure that customers would not face reduced choice or higher prices as a result of this takeover," Competition Commissioner Neelie Kroes said in a statement.Rival? Really? Didn't Marten Mickos say that MySQL wasn't, or didn't want to be, a competitor of Oracle?
Where is the reduced choice?
Besides (please correct me if I am wrong), aren't these customers paying for support and not the product itself?
Anyway, there are plenty of database options out there. If MySQL does fork, it might just be better for everyone involved because they'll take it in a new or different direction.
Please help this confused soul and explain to me how this might be a monopoly.
Sunday, September 13, 2009
Database Tutoring
Last week a friend of mine sent over a craigslist posting, someone looking for a tutor. Here's the ad:
We spoke on Saturday for about an hour and I received all the materials necessary to start doing research including a sample database (in Access).
I have to say I'm pretty excited about it. I thoroughly enjoy trying to explain database concepts so that others (non-techies) can understand. It's a Masters level class filled with students from Computer Science and from an Education Technology tract. Bet you can guess which side my "student" falls in.
Seems a little odd that the Educational Technology folks are in the class, but I think it's a good thing. When they need an application in the future, they'll have a much better grasp of what to ask for and hopefully they'll be more involved in the process.
I'll use this space both for reporting on progress and helping to explain things. Wish us luck!
Looking for an experienced SQL Database Systems analyst to help with homework assignments for a graduate level database course. Would like to meet 2 times per week (for 2 hours each session) over the next four months. Evening, weekends or Wednesdays preferred. The candidate must be able to explain the technical to the non-technical. Please reply with resume and availablility.I replied immediately and heard back the next day. I sent my resume but I thought the blog would be more appropriate. Apparently it was enough.
Course Topics Are:
* Relational Model and Languages ( SQL)
* Database Analysis and Design
* Methodology (Conceptual and Logical Design)
* Social, Legal, etc. Issues
* Distributed DBMSs and Replication
* Object DBMSs
* The Web and DBMSs
* Business Intelligence
We spoke on Saturday for about an hour and I received all the materials necessary to start doing research including a sample database (in Access).
I have to say I'm pretty excited about it. I thoroughly enjoy trying to explain database concepts so that others (non-techies) can understand. It's a Masters level class filled with students from Computer Science and from an Education Technology tract. Bet you can guess which side my "student" falls in.
Seems a little odd that the Educational Technology folks are in the class, but I think it's a good thing. When they need an application in the future, they'll have a much better grasp of what to ask for and hopefully they'll be more involved in the process.
I'll use this space both for reporting on progress and helping to explain things. Wish us luck!
Announcing the World's First OLTP Database Machine with Sun FlashFire Technology
Apparently Larry Ellison is announcing a new product on Tuesday, an Oracle OLTP database machine with Sun FlashFire technology. Sign-up for the web cast here.
I first saw it here, at Francisco Munoz Alvarez's Oracle NZ blog.
Mark Rittman has some more speculation here.
Greg Rahn at Structured Data has one as well.
Talk about shiny new objects...
I first saw it here, at Francisco Munoz Alvarez's Oracle NZ blog.
Mark Rittman has some more speculation here.
Greg Rahn at Structured Data has one as well.
Talk about shiny new objects...
T-Shirt: DBA Books
I wouldn't say I have nothing to do or that I am bored, I just like making t-shirts for some reason.

Since it's too small to read:

Since it's too small to read:
Thursday, September 10, 2009
Random Things: Volume #7
Another Death of the RDBMS Article
I found another "Death of the RDBMS" article this week. This one is called, The End of a DBMS Era (Might be Upon Us), by Michael Stonebraker.
An Idea?
Since everyone's all abuzz about 11gR2, I think it's a good time to bring this up. Back in June, I was having problems debugging an INSERT statement. I kept getting, not enough values.
I came up with this:
Oracle OpenWorld
Just one month from today the conference begins. Sadly, I won't be able to attend this year, but I doubt getting information, on a near real-time basis, will be difficult.
A reminder, I've been tagging anything and everything related to OpenWorld via Google Reader, you can see the public page here. A direct link to the feed can be found here.
Alex Gorbachev announced the details of the Oracle Blogger meetup. More details at the Oracle Community page. Rumor has it that Stanley, the ACE Director will be there.
I found another "Death of the RDBMS" article this week. This one is called, The End of a DBMS Era (Might be Upon Us), by Michael Stonebraker.
Moreover, the code line from all of the major vendors is quite elderly, in all cases dating from the 1980s. Hence, the major vendors sell software that is a quarter century old, and has been extended and morphed to meet today’s needs. In my opinion, these legacy systems are at the end of their useful life. They deserve to be sent to the "home for tired software."I'm not quite sure why old code is necessarily bad. From the comments:
And of all the valid criticisms of a model or a technology, "elderly" and "tired" are worse than useless. Do we believe that technology builds on prior discoveries, or that new technology throws older discoveries away? By such a standard, we would stop teaching Boolean logic, Turing machines, and all the other things that predate us.Also in the comments you learn that Mr. Stonebraker is the CTO of Vertica. Makes perfect sense...I guess. Would have been nice to see that up top though.
An Idea?
Since everyone's all abuzz about 11gR2, I think it's a good time to bring this up. Back in June, I was having problems debugging an INSERT statement. I kept getting, not enough values.
I came up with this:
INSERT INTO my_tableVote for it here on Oracle Mix. Maybe someone will take notice and implement it in 13h.
( id => seq.nexval,
create_date => SYSDATE,
update_date => SYSDATE,
col1 => 'A',
col2 => 'SOMETHING',
col3 => 'SOMETHING',
col4 => 'SOMETHING',
col5 => 'SOMETHING',
col6 => 'SOMETHING',
col7 => 'SOMETHING',
col8 => 'SOMETHING',
col9 => 'SOMETHING',
col10 => 'SOMETHING',
col11 => 'SOMETHING',
col12 => 'SOMETHING',
col13 => 'SOMETHING',
col14 => 'SOMETHING' );
Oracle OpenWorld
Just one month from today the conference begins. Sadly, I won't be able to attend this year, but I doubt getting information, on a near real-time basis, will be difficult.
A reminder, I've been tagging anything and everything related to OpenWorld via Google Reader, you can see the public page here. A direct link to the feed can be found here.
Alex Gorbachev announced the details of the Oracle Blogger meetup. More details at the Oracle Community page. Rumor has it that Stanley, the ACE Director will be there.
Oracle To Sun Customers
Found via @dannorris

(Twitter IS useful!)

Taking Oracle at their word, that's gotta make you feel pretty good as a Sun customer.
(Twitter IS useful!)
We're in it to win itLove that.
Taking Oracle at their word, that's gotta make you feel pretty good as a Sun customer.
Wednesday, September 9, 2009
SQL Developer: Drill Down Reports
Finally, finally I've figured this out. I've googled "SQL Developer Drillable Reports" to no avail. The solution kept alluding me.
The first result you should get back is one from a fellow Tampan (Tampon?), Lewis Cunningham, from July 2006. OK, it's a bit old (I think it was still called Raptor back then), but I'll give it a try.
In it, Lewis talks about creating additional "pseudo" columns, SDEV_LINK_NAME, SDEV_LINK_OWNER, SDEV_LINK_OBJECT which appear to map to the corresponding columns in DBA_OBJECTS.
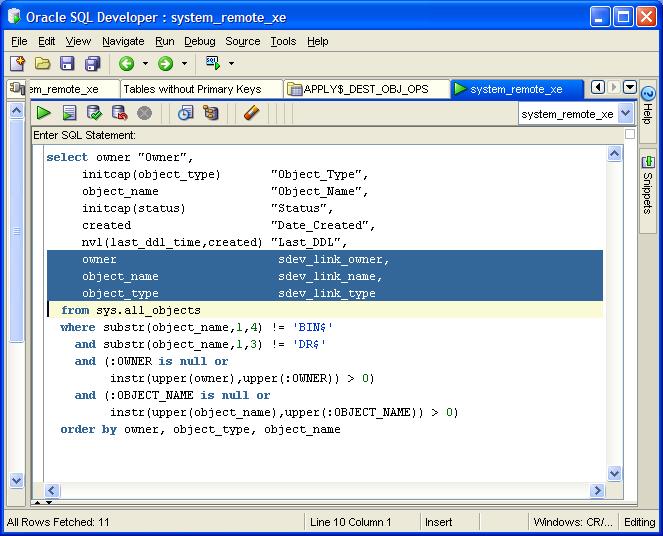
I tried that, and got...nothing. I tried changing the alias(es) to match the column I was using, again, to no avail.
Let me back up just a tad, I'm trying to create some reports based on the PLSQL_PROFILER_% tables:
* PLSQL_PROFILER_RUNS
* PLSQL_PROFILER_UNITS
* PLSQL_PROFILER_DATA
It's annoying to have to rewrite the SQL everytime. I did create a @profile script, but I had to pass the RUNID; so first, I had to know the RUNID.
So I took to Twitter as I know Kris Rice hangs out there sometimes.



That was last week, and I have been unable to get this to work. I could have sworn Kris had a good tutorial on it, but I think I confused it with the extensions you can create.
Anyway, I'm at it again tonight and I end up back at the link Kris originally pointed me to. For some reason (cough) I missed this crucial little nugget this first time
To recap, go to the Reports tab, right click on a folder (I have one named "profiler") and select Add Report.
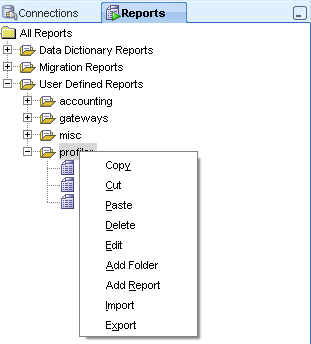
I fill out the Name, Description and Tooltip (optional)
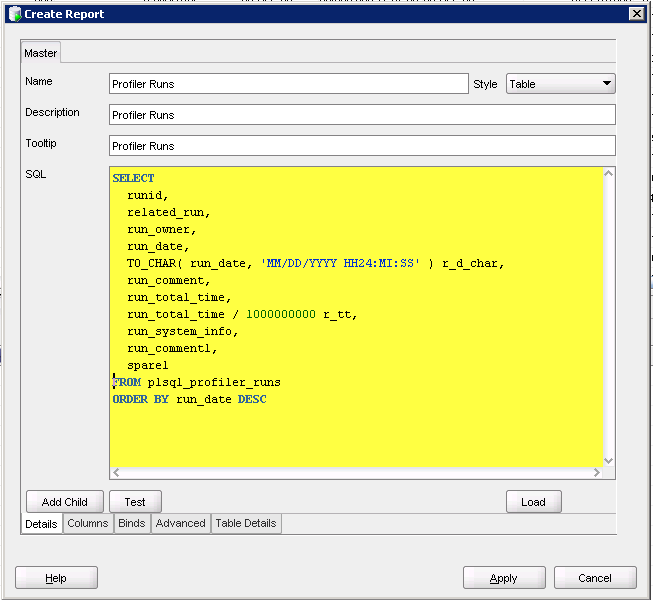
Hit Apply which saves my report. Now I want a report that on PLSQL_PROFILER_UNITS that accepts the RUNID as an IN parameter.
First, create the report:
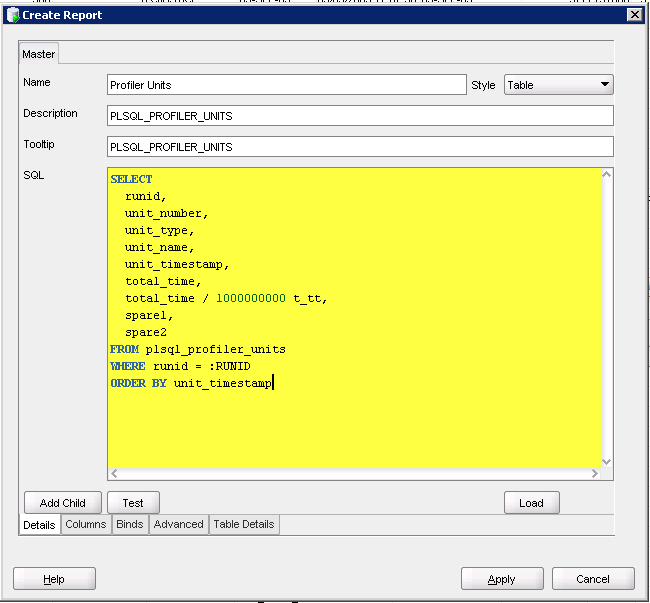
Go to the Binds tab and fill in the fields
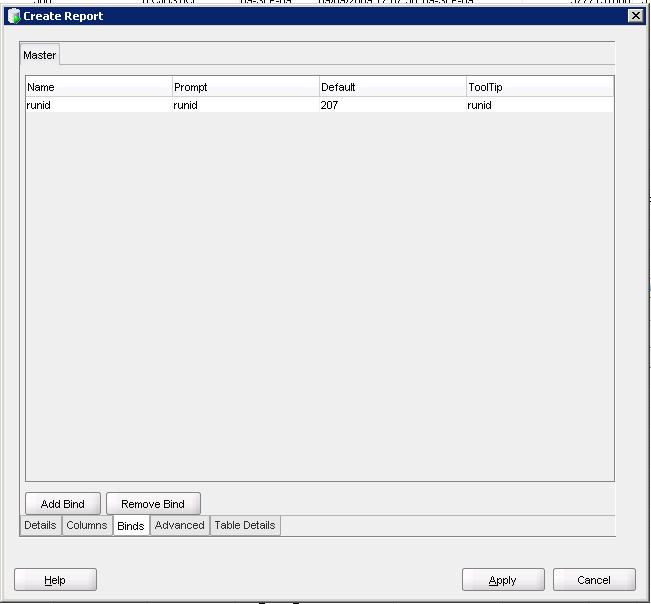
Go to the Advanced tab and fill in the name of the report
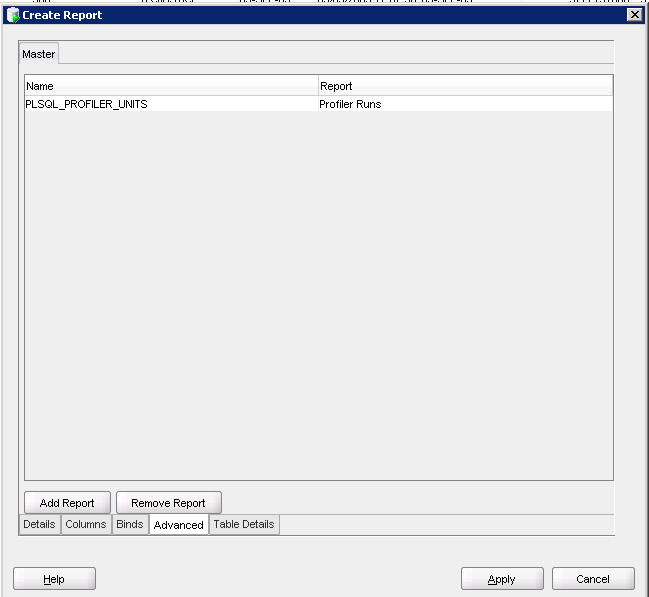
Now, select your first report, right click, go to Reports and select the report you just created
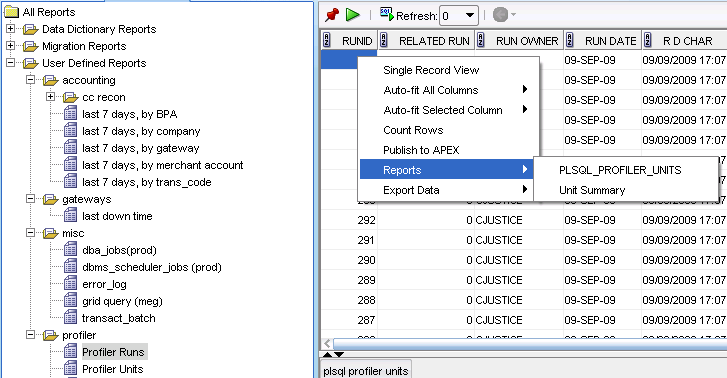
Perfect!
Just a small reminder, the bind parameters are CASE SENSITIVE!
The first result you should get back is one from a fellow Tampan (Tampon?), Lewis Cunningham, from July 2006. OK, it's a bit old (I think it was still called Raptor back then), but I'll give it a try.
In it, Lewis talks about creating additional "pseudo" columns, SDEV_LINK_NAME, SDEV_LINK_OWNER, SDEV_LINK_OBJECT which appear to map to the corresponding columns in DBA_OBJECTS.
I tried that, and got...nothing. I tried changing the alias(es) to match the column I was using, again, to no avail.
Let me back up just a tad, I'm trying to create some reports based on the PLSQL_PROFILER_% tables:
* PLSQL_PROFILER_RUNS
* PLSQL_PROFILER_UNITS
* PLSQL_PROFILER_DATA
It's annoying to have to rewrite the SQL everytime. I did create a @profile script, but I had to pass the RUNID; so first, I had to know the RUNID.
So I took to Twitter as I know Kris Rice hangs out there sometimes.
That was last week, and I have been unable to get this to work. I could have sworn Kris had a good tutorial on it, but I think I confused it with the extensions you can create.
Anyway, I'm at it again tonight and I end up back at the link Kris originally pointed me to. For some reason (cough) I missed this crucial little nugget this first time
(the bind variable is case-sensitive)Really? Could it be that easy? I UPPERed RUNID and voila! It worked!
To recap, go to the Reports tab, right click on a folder (I have one named "profiler") and select Add Report.
I fill out the Name, Description and Tooltip (optional)
Hit Apply which saves my report. Now I want a report that on PLSQL_PROFILER_UNITS that accepts the RUNID as an IN parameter.
First, create the report:
Go to the Binds tab and fill in the fields
Go to the Advanced tab and fill in the name of the report
Now, select your first report, right click, go to Reports and select the report you just created
Perfect!
Just a small reminder, the bind parameters are CASE SENSITIVE!
Tuesday, September 8, 2009
Views: Complex Join Use Primary Keys?
Views have been on my mind quite a bit lately.
Last night I began to wonder if it makes a difference which key you use in the view. Logically, I thought, it would make a difference.
Here's my create scripts:
Admittedly, I can't explain all the "magic" behind it, I'm hoping someone out there could help to explain. Logically, it makes sense as the Primary Key allows you the fastest access to a specific record (discounting the rowid).
Last night I began to wonder if it makes a difference which key you use in the view. Logically, I thought, it would make a difference.
Here's my create scripts:
CREATE TABLE tSo I wanted to see if Oracle took a different path depending on how I built the view.
(
my_id NUMBER(12)
CONSTRAINT pk_myid PRIMARY KEY
);
INSERT INTO t( my_id )
SELECT rownum
FROM dual
CONNECT BY LEVEL <= 1000000;
CREATE TABLE t_child
AS
SELECT rownum child_id, my_id
FROM t;
ALTER TABLE t_child
ADD CONSTRAINT pk_childid
PRIMARY KEY ( child_id );
ALTER TABLE t_child
ADD CONSTRAINT fk_myid_tchild
FOREIGN KEY ( my_id )
REFERENCES t( my_id );
CREATE INDEX idx_myid_tchild
ON t_child( my_id );
CREATE TABLE t_child_2
AS
SELECT rownum child_id_2, child_id
FROM t_child;
ALTER TABLE t_child_2
ADD CONSTRAINT pk_childid2
PRIMARY KEY ( child_id_2 );
ALTER TABLE t_child_2
ADD CONSTRAINT fk_childid_tchild2
FOREIGN KEY ( child_id )
REFERENCES t_child( child_id );
CREATE INDEX idx_childid_tchild2
ON t_child_2( child_id );
CREATE OR REPLACESo now I run a couple of tests to see what happens when I SELECT on those columns (reminder, those are not the primary keys, they are indexed foreign keys).
VIEW vw_test
AS
SELECT
tc.my_id,--note that isn't the PK from T
t2.child_id--again, not the PK from T_CHILD
FROM
t,
t_child tc,
t_child_2 t2
WHERE t.my_id = tc.my_id
AND tc.child_id = t2.child_id;
CJUSTICE@TESTING>EXPLAIN PLAN FOROK, so it did what I expected, it failed to get the record based on the primary key. I'll do it again, with the same construct as the view, but using the PK from T.
2 SELECT *
3 FROM vw_test
4 WHERE my_id = 1;
Explained.
Elapsed: 00:00:00.00
CJUSTICE@TESTING>
CJUSTICE@TESTING>SELECT * FROM TABLE( dbms_xplan.display );
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 1671340153
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 14 | 6 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 1 | 14 | 6 (0)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| T_CHILD | 1 | 9 | 4 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | IDX_MYID_TCHILD | 1 | | 3 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | IDX_CHILDID_TCHILD2 | 1 | 5 | 2 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("TC"."MY_ID"=1)
filter("TC"."MY_ID" IS NOT NULL)
4 - access("TC"."CHILD_ID"="T2"."CHILD_ID")
CJUSTICE@TESTING>EXPLAIN PLAN FORGood. Now I'll recreate the view using the primary key and see if we get the same result.
2 SELECT
3 tc.my_id,
4 t2.child_id
5 FROM
6 t,
7 t_child tc,
8 t_child_2 t2
9 WHERE t.my_id = tc.my_id
10 AND tc.child_id = t2.child_id
11 AND t.my_id = 1;
Explained.
Elapsed: 00:00:00.01
CJUSTICE@TESTING>
CJUSTICE@TESTING>@explain
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 4007286110
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 18 | 7 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 1 | 18 | 7 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 1 | 13 | 5 (0)| 00:00:01 |
|* 3 | INDEX UNIQUE SCAN | PK_MYID | 1 | 4 | 2 (0)| 00:00:01 |
| 4 | TABLE ACCESS BY INDEX ROWID| T_CHILD | 1 | 9 | 3 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | IDX_MYID_TCHILD | 1 | | 2 (0)| 00:00:01 |
|* 6 | INDEX RANGE SCAN | IDX_CHILDID_TCHILD2 | 1 | 5 | 2 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("T"."MY_ID"=1)
5 - access("TC"."MY_ID"=1)
6 - access("TC"."CHILD_ID"="T2"."CHILD_ID")
CREATE OR REPLACENow I'll try the same test using the FK on T_CHILD_2, CHILD_ID. No need to change the view as it's already there.
VIEW vw_test
AS
SELECT
t.my_id,
t2.child_id
FROM
t,
t_child tc,
t_child_2 t2
WHERE t.my_id = tc.my_id
AND tc.child_id = t2.child_id;
CJUSTICE@TESTING>EXPLAIN PLAN FOR
2 SELECT *
3 FROM vw_test
4 WHERE my_id = 1;
Explained.
Elapsed: 00:00:00.03
CJUSTICE@TESTING>@explain
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 4007286110
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 18 | 7 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 1 | 18 | 7 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 1 | 13 | 5 (0)| 00:00:01 |
|* 3 | INDEX UNIQUE SCAN | PK_MYID | 1 | 4 | 2 (0)| 00:00:01 |
| 4 | TABLE ACCESS BY INDEX ROWID| T_CHILD | 1 | 9 | 3 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | IDX_MYID_TCHILD | 1 | | 2 (0)| 00:00:01 |
|* 6 | INDEX RANGE SCAN | IDX_CHILDID_TCHILD2 | 1 | 5 | 2 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("T"."MY_ID"=1)
5 - access("TC"."MY_ID"=1)
6 - access("TC"."CHILD_ID"="T2"."CHILD_ID")
CJUSTICE@TESTING>EXPLAIN PLAN FORAnd now using the PK
2 SELECT *
3 FROM vw_test
4 WHERE child_id = 1;
Explained.
Elapsed: 00:00:00.01
CJUSTICE@TESTING>@EXPLAIN
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 474290160
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 18 | 6 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 1 | 18 | 6 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 1 | 13 | 4 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| T_CHILD | 1 | 9 | 3 (0)| 00:00:01 |
|* 4 | INDEX UNIQUE SCAN | PK_CHILDID | 1 | | 2 (0)| 00:00:01 |
|* 5 | INDEX UNIQUE SCAN | PK_MYID | 989K| 3863K| 1 (0)| 00:00:01 |
|* 6 | INDEX RANGE SCAN | IDX_CHILDID_TCHILD2 | 1 | 5 | 2 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("TC"."CHILD_ID"=1)
5 - access("T"."MY_ID"="TC"."MY_ID")
6 - access("T2"."CHILD_ID"=1)
CJUSTICE@TESTING>EXPLAIN PLAN FORLooks like a much better path when I use the PK in the view definition. Note to self, if building complex views, don't use the Foreign Key column, use the Primary Key column.
2 SELECT
3 tc.my_id,
4 t2.child_id
5 FROM
6 t,
7 t_child tc,
8 t_child_2 t2
9 WHERE t.my_id = tc.my_id
10 AND tc.child_id = t2.child_id
11 AND tc.child_id = 1;
Explained.
Elapsed: 00:00:00.01
CJUSTICE@TESTING>
CJUSTICE@TESTING>@explain
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 3182888138
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 14 | 5 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 1 | 14 | 5 (0)| 00:00:01 |
|* 2 | TABLE ACCESS BY INDEX ROWID| T_CHILD | 1 | 9 | 3 (0)| 00:00:01 |
|* 3 | INDEX UNIQUE SCAN | PK_CHILDID | 1 | | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | IDX_CHILDID_TCHILD2 | 1 | 5 | 2 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("TC"."MY_ID" IS NOT NULL)
3 - access("TC"."CHILD_ID"=1)
4 - access("T2"."CHILD_ID"=1)
Admittedly, I can't explain all the "magic" behind it, I'm hoping someone out there could help to explain. Logically, it makes sense as the Primary Key allows you the fastest access to a specific record (discounting the rowid).
Tri-lingual?
A friend of mine, a couple of jobs back, told me this great joke.
We were walking out to our cars after a fun day at work and he proceeds to tell the joke.
Srini: "What do you call someone who speaks 3 languages?"
Me: "Tri-lingual?"
Srini: "What do you call someone who speaks 2 languages?"
Me: "Bi-linqual?"
Srini: "What do you call someone who speaks 1 language?"
Me: "I don't know, mono-lingual?"
Srini: "American."
Srini was not American born, nor is that is full name. He also spoke 3 or 4 languages and he was giving me a hard time for being "mono-lingual."
His full name consists of a whopping 26 letters. I went to great effort to learn how to pronounce his name prior to his interview. Took about 4 weeks to get it right.
Not really sure why I recalled that particular joke today...but it was a good one. I miss Srini...such a good sport and a fun guy. If you ever run into him, ask him, "Can I tie that for you?" and see the different shades of red he turns.
We were walking out to our cars after a fun day at work and he proceeds to tell the joke.
Srini: "What do you call someone who speaks 3 languages?"
Me: "Tri-lingual?"
Srini: "What do you call someone who speaks 2 languages?"
Me: "Bi-linqual?"
Srini: "What do you call someone who speaks 1 language?"
Me: "I don't know, mono-lingual?"
Srini: "American."
Srini was not American born, nor is that is full name. He also spoke 3 or 4 languages and he was giving me a hard time for being "mono-lingual."
His full name consists of a whopping 26 letters. I went to great effort to learn how to pronounce his name prior to his interview. Took about 4 weeks to get it right.
Not really sure why I recalled that particular joke today...but it was a good one. I miss Srini...such a good sport and a fun guy. If you ever run into him, ask him, "Can I tie that for you?" and see the different shades of red he turns.
Monday, September 7, 2009
Data vs. Information
Last week in The Case For Views on the very last line I said
Then there was twitter, where he sent me a few more links on the subject.
I'm pretty sure he was fired up.
Once a week or so, we'll get together over beers and have excellent conversations. Occasionally, I'll try to hold my ground from the database perspective. Last week we had a discussion about whether the database should be making web service calls.
Security aside, I thought it was appropriate given the size and skills of the shop, but he and our other friend staunchly disagreed.
Point is, we have some great conversations. It has never come down to "You are stupid!" or anything like that, it's a conversation with each side presenting their arguments.
Since my friend has like 28 degrees in Engineering, I've learned to give him the benefit of the doubt, so I wanted to study up on it.
I asked the oracle-l mailing list on Friday.
My contention, or what I have heard and read, is that a database stores data, only through the use of SQL or some reporting tool, does that data get turned into information. I don't know where I heard or read that for the first time, but I've probably been saying it for years.
Through my friends response and others on the mailing list, I probably need to rethink that particular statement.
Here are some relevant links provided by my friend and others on the oracle-l mailing list:
Principles of Communication Enginnering, By John M. Wozencraft, Irwin Mark Jacobs
Information Theory and Reliable Communication, By Robert G. Gallager
Nuno Suto, aka Noons suggested Fabian Pascal, which can be read here. He also suggested reading up on Chris Date and Ted Codd as well as
Conceptual Schema and Relational Database Design: A Fact Oriented Approach, By G. M. Nijssen, T. A. Halpin
Have you ever used the phrase, "data into information" or some derivation there of? I'd like to track down where I first came across it if possible. Thoughts on Data vs. Information as separate entities?
Records in a table typically constitute data. Tables, joined together, in a view, tend to turn that data into information.That elicited a very, very strong reaction from a good friend and mentor. In the comments he left this
Turn data into information? That doesn't make a whole lot of sense to me-- All data is information. Can you clarify that statement a little?On the face of it, that's not a very strong reaction. He tends to be a lurker though, rarely leaving comments.
Then there was twitter, where he sent me a few more links on the subject.
I'm pretty sure he was fired up.
Once a week or so, we'll get together over beers and have excellent conversations. Occasionally, I'll try to hold my ground from the database perspective. Last week we had a discussion about whether the database should be making web service calls.
Security aside, I thought it was appropriate given the size and skills of the shop, but he and our other friend staunchly disagreed.
Point is, we have some great conversations. It has never come down to "You are stupid!" or anything like that, it's a conversation with each side presenting their arguments.
Since my friend has like 28 degrees in Engineering, I've learned to give him the benefit of the doubt, so I wanted to study up on it.
I asked the oracle-l mailing list on Friday.
My contention, or what I have heard and read, is that a database stores data, only through the use of SQL or some reporting tool, does that data get turned into information. I don't know where I heard or read that for the first time, but I've probably been saying it for years.
Through my friends response and others on the mailing list, I probably need to rethink that particular statement.
Here are some relevant links provided by my friend and others on the oracle-l mailing list:
Principles of Communication Enginnering, By John M. Wozencraft, Irwin Mark Jacobs
Information Theory and Reliable Communication, By Robert G. Gallager
Nuno Suto, aka Noons suggested Fabian Pascal, which can be read here. He also suggested reading up on Chris Date and Ted Codd as well as
Conceptual Schema and Relational Database Design: A Fact Oriented Approach, By G. M. Nijssen, T. A. Halpin
Have you ever used the phrase, "data into information" or some derivation there of? I'd like to track down where I first came across it if possible. Thoughts on Data vs. Information as separate entities?
Friday, September 4, 2009
Random Things: Volume #6
News
Of course the big news of the week is the latest release of the Oracle database, 11gR2. Everyone and their mother wrote about it, including yours truly. Seemed like a fun game to get a post out as quickly as possible.
Eddie Awad has compiled a pretty nice list of links to the "What's New" documentation section for the past 6 releases.
Sun + Oracle is faster
EU Investigates Oracle Bid for Sun
Two weeks ago the Department of Justice approved the Oracle/Sun deal. Now the EU has set a January 10, 2010 deadline for it's response delaying the acquisition further. I know both Oracle and Sun are international/global companies, but they are based in the US. How exactly does the EU have authority? A monopoly you say? Bollocks I say. There are plenty of choices out there. Oh well.
Coding
What is the deal with mixed-case PL/SQL? I have a pretty strong aversion towards it. PL/SQL is not Java, Ruby, .NET or any other programming language. Pick a case, any case, just don't mix them.
DBMS_PROFILER
Back in July I had a nice conversation with Cary Millsap over email. I had asked him to explain the difference between logging, debugging and instrumentation. He suggested checking out DBMS_PROFILER. I've been able to try it out recently (details/examples coming soon) and it's pretty freaking cool...and scary. I got to see the (many) steps that are taken while performing a specific task.
OpenWorld
Last week I announced I wasn't going, recanted and then this week recanted the recant. Fun huh?
Of course the big news of the week is the latest release of the Oracle database, 11gR2. Everyone and their mother wrote about it, including yours truly. Seemed like a fun game to get a post out as quickly as possible.
Eddie Awad has compiled a pretty nice list of links to the "What's New" documentation section for the past 6 releases.
Sun + Oracle is faster
Oracle and Sun together are hard to match. Just ask IBM. Its fastest server now runs an impressive 6 million TPC-C transactions, but on October 14 at Oracle OpenWorld, we'll reveal the benchmark numbers that prove that even IBM DB2 running on IBM's fastest hardware can't match the speed and performance of Oracle Database on Sun systems. Check back on October 14 as we demonstrate Oracle's commitment to Sun hardware and Sun SPARC.
EU Investigates Oracle Bid for Sun
Two weeks ago the Department of Justice approved the Oracle/Sun deal. Now the EU has set a January 10, 2010 deadline for it's response delaying the acquisition further. I know both Oracle and Sun are international/global companies, but they are based in the US. How exactly does the EU have authority? A monopoly you say? Bollocks I say. There are plenty of choices out there. Oh well.
Coding
What is the deal with mixed-case PL/SQL? I have a pretty strong aversion towards it. PL/SQL is not Java, Ruby, .NET or any other programming language. Pick a case, any case, just don't mix them.
DBMS_PROFILER
Back in July I had a nice conversation with Cary Millsap over email. I had asked him to explain the difference between logging, debugging and instrumentation. He suggested checking out DBMS_PROFILER. I've been able to try it out recently (details/examples coming soon) and it's pretty freaking cool...and scary. I got to see the (many) steps that are taken while performing a specific task.
OpenWorld
Last week I announced I wasn't going, recanted and then this week recanted the recant. Fun huh?
Thursday, September 3, 2009
The Case For Views
I recently had to "defend" my use of views.
To me, they seem natural. Using them is almost always a good thing to do. I've met those that don't really care for them...I just never understood why. Then again, those same people are still not convinced of PL/SQL APIs. Maybe there is something to that mindset...
Being forced to articulate one's views is a good thing, it's part of why I blog. I won't lie though, it gets frustrating to have do this, seemingly, all the time.
I'm going to do it here, again.
Complex Joins
No, I'm not afraid of joins. I am afraid of others who are afraid of joins though. More specifically, I'm afraid of those who aren't proficient at writing SQL. Let me do it, once, and let everyone else have access to the view. Besides, I'm the subject matter expert (SME) on the given set of tables, so it follows that I should create the interface to those tables.
Yes, I said interface. It's exactly what a view is and interface to the underlying data.
Encapsulation
Write it once and let it propogate everywhere.
When I had to "defend" my use of views, I mistakenly used the example of adding columns. Oops. That would (possibly) require changes throughout the system. I meant to say remove columns, in which case you could keep the placeholder in the view using NULL without having to change all of the code. This does not mean that proper analysis does not need to be performed, it does, but you could possibly get away with not having to change everything that references the view.
My second example was a derived value. This makes more sense to some people thankfully. I've seen the same calculation done on a specific field done 10s, even 100s of times throughout the code. Why not do it one time? Perfect use for views.
Security
Following the least privileges necessary to perform a given action, views allow you to give access to the data without direct access to the tables. Views can also be used to hide or mask data that certain individuals should not have access to. In conjunction with VPD or Application Contexts, it's a powerful way to prevent unauthorized access.
Maintenance
Maintenance has been alluded to above, but not explicitly stated.
For derived values: If you have a derived or calculated value and that calculation is performed all over the place, what happens when it changes? You have to update it everywhere. If you had used a view, change it once and it propogates everywhere. What was once a project is now a "simple" code change. This affects IT in how they choose and assign resources as well as the Business.
For complex joins: What if one table is no longer used or needed? What if that table is littered throughout the code base? You have a project on your hands.
If that table were part of a view, you could "simply" remove it, keep the columns in the view and you're done. There might be places where code needs to be adjusted, but overall, you have a much smaller impact. That's a good thing.
Other
I tried putting the following statement in a category up above, but couldn't make it fit.
Records in a table typically constitute data. Tables, joined together, in a view, tend to turn that data into information.
To me, they seem natural. Using them is almost always a good thing to do. I've met those that don't really care for them...I just never understood why. Then again, those same people are still not convinced of PL/SQL APIs. Maybe there is something to that mindset...
Being forced to articulate one's views is a good thing, it's part of why I blog. I won't lie though, it gets frustrating to have do this, seemingly, all the time.
I'm going to do it here, again.
Complex Joins
No, I'm not afraid of joins. I am afraid of others who are afraid of joins though. More specifically, I'm afraid of those who aren't proficient at writing SQL. Let me do it, once, and let everyone else have access to the view. Besides, I'm the subject matter expert (SME) on the given set of tables, so it follows that I should create the interface to those tables.
Yes, I said interface. It's exactly what a view is and interface to the underlying data.
Encapsulation
Write it once and let it propogate everywhere.
When I had to "defend" my use of views, I mistakenly used the example of adding columns. Oops. That would (possibly) require changes throughout the system. I meant to say remove columns, in which case you could keep the placeholder in the view using NULL without having to change all of the code. This does not mean that proper analysis does not need to be performed, it does, but you could possibly get away with not having to change everything that references the view.
My second example was a derived value. This makes more sense to some people thankfully. I've seen the same calculation done on a specific field done 10s, even 100s of times throughout the code. Why not do it one time? Perfect use for views.
Security
Following the least privileges necessary to perform a given action, views allow you to give access to the data without direct access to the tables. Views can also be used to hide or mask data that certain individuals should not have access to. In conjunction with VPD or Application Contexts, it's a powerful way to prevent unauthorized access.
Maintenance
Maintenance has been alluded to above, but not explicitly stated.
For derived values: If you have a derived or calculated value and that calculation is performed all over the place, what happens when it changes? You have to update it everywhere. If you had used a view, change it once and it propogates everywhere. What was once a project is now a "simple" code change. This affects IT in how they choose and assign resources as well as the Business.
For complex joins: What if one table is no longer used or needed? What if that table is littered throughout the code base? You have a project on your hands.
If that table were part of a view, you could "simply" remove it, keep the columns in the view and you're done. There might be places where code needs to be adjusted, but overall, you have a much smaller impact. That's a good thing.
Other
I tried putting the following statement in a category up above, but couldn't make it fit.
Records in a table typically constitute data. Tables, joined together, in a view, tend to turn that data into information.

Wednesday, September 2, 2009
Intelligent Business Intelligence: 4 Keys to a Successful BI Approach
Ted claims he had more than 3 readers (mom, sister, wife) last time, so he's back for more.
One of the things I really like about this piece is the view into Ted's mind as he is going through the process. I think many of us can (ultimately) can figure out the technical side, it's the When, What and Why that become the bigger questions. Enjoy!
One of the greatest challenges business intelligence (BI) customers face is the adoption of BI solutions. Vendor selection and procurement, implantation and validation, and technical skill acquisition are challenges that can be met with some inspiration and perspiration. Many of the critical organizational components are often in place for successful BI adoption (executive, managerial, technical, functional), but too often they are not orchestrated and sustained properly to ensure success. (Full disclosure: I am learning these lessons through full and repeated BI fail of my own.)
Often BI is thought of in terms of a technology solution provided by IT. Less often it is thought of in terms of a functional solution provided by various report writers and developers employed across an organization. Less often still, BI is thought of in terms of a sustained function of the executive team. Obviously, it is all three of these working together. Everyone knows that and speaks and writes about it everywhere. So why are many BI projects less than successful? (See Business Intelligence Software Adoption Lags BI Vendors' Perception and Business Intelligence Adoption Low and Falling.)
From what I have seen in my own organization and through a few consulting engagements, successful organizations do these four things really well around their BI approach:
Filling Key Roles
Quite a bit of emphasis seems to be placed on filling roles at the management level and at the subject matter expert (SME) level. The idea being that if you can pair up a good IT director with a good, say, payroll expert to work on BI then good things will happen. Good things may happen, but it is seldom enough. Two roles I see as critical to success are a committed, long-term C-level champion and a hard-core and committed BI ninja to grind persistently and patiently on data validation. Here is a good article that describes key roles well . If the pressure from the top and from the bottom are not consistently applied, then those in the middle tend to stay comfortably frozen.
Thinking Full Circle
This is hard to do and usually takes imaginative thinkers. My current organization usually does a good job at thinking creatively - even about its business challenges. The idea here is to structure data collection in such a way that you anticipate using that data for BI. One of our vice presidents has made this jump. He develops surveys that will align with existing ERP data, will add valuable and actionable information to his decision making, and are repeatable and repeated every year. This was difficult for him to start because he really needed to focus on the end result before most of the data was collected. Here is a good article that spells out some of the considerations needed to think full circle. You may also want to read some of what Gartner has to say about BI.
These first two are fairly standard keys to success. I've seen a couple of "softer" elements, though, that really make a difference when it comes to BI adoption.
Balancing Quantitative and Qualitative Information
This is where fear creeps in. It seems that many executives I have met are just a little skittish about making decisions based on quantitative analytics. This is the promise of BI, isn't it? Most pitches I see have some version of "cost control through real-time analytics." Our vice president for operations wants real-time analytics on overtime hours so that he can spot trends and possibly curb peaks. That is good stuff. When the idea of basing decisions on quantitative analytics comes up in a group of executives, though, they often balk at it. They see it as a binary choice between basing decisions on the numbers and basing decisions on their experience or knowledge or instinct. This is when we need to step in. I'll extend Jake's recent medical analogy and suggest that we may need to also act as psychologists. It isn't a binary choice; it is both. It is okay to inform your decisions. It is okay to overrule the numbers. Relax . . . just don't be a blinker.
Accepting Incompleteness
This is a tough thing for a lot of people to do. Many people assume that if something is not completely finished it is not usable. When it comes to information, though, being incomplete is natural. Still, when it comes to BI, many consumers will argue that it only gives them "half of the story" or "part of the big picture." That is usually true. I argue that with or without BI, most critical business decisions are made with incomplete information. Even the most complete set of information will still only give an indication of how key areas of your business are performing. (KPI anyone?) The idea here is to understand and accept that BI is incomplete and emerging. It is okay to get your Wabi Sabi on about the big picture and know that it may have blurred edges. After all, most executives I know want to use their own experience and knowledge to fill out the big picture (see above).
If you want to call me out or talk me down, hit the comments section or send me a note. If you prefer to call me out in person, I'll be at Open World , at Circuit in DC , and always at Alliance.
Ted [ linkedin | twitter ] is Vice President for Communications at the Higher Education User Group, MBA and MSIS student at the Johns Hopkins University, Director of Administrative Systems at MICA, and blogger at badgerworks.
One of the things I really like about this piece is the view into Ted's mind as he is going through the process. I think many of us can (ultimately) can figure out the technical side, it's the When, What and Why that become the bigger questions. Enjoy!
One of the greatest challenges business intelligence (BI) customers face is the adoption of BI solutions. Vendor selection and procurement, implantation and validation, and technical skill acquisition are challenges that can be met with some inspiration and perspiration. Many of the critical organizational components are often in place for successful BI adoption (executive, managerial, technical, functional), but too often they are not orchestrated and sustained properly to ensure success. (Full disclosure: I am learning these lessons through full and repeated BI fail of my own.)
Often BI is thought of in terms of a technology solution provided by IT. Less often it is thought of in terms of a functional solution provided by various report writers and developers employed across an organization. Less often still, BI is thought of in terms of a sustained function of the executive team. Obviously, it is all three of these working together. Everyone knows that and speaks and writes about it everywhere. So why are many BI projects less than successful? (See Business Intelligence Software Adoption Lags BI Vendors' Perception and Business Intelligence Adoption Low and Falling.)
From what I have seen in my own organization and through a few consulting engagements, successful organizations do these four things really well around their BI approach:
Filling Key Roles
Quite a bit of emphasis seems to be placed on filling roles at the management level and at the subject matter expert (SME) level. The idea being that if you can pair up a good IT director with a good, say, payroll expert to work on BI then good things will happen. Good things may happen, but it is seldom enough. Two roles I see as critical to success are a committed, long-term C-level champion and a hard-core and committed BI ninja to grind persistently and patiently on data validation. Here is a good article that describes key roles well . If the pressure from the top and from the bottom are not consistently applied, then those in the middle tend to stay comfortably frozen.
Thinking Full Circle
This is hard to do and usually takes imaginative thinkers. My current organization usually does a good job at thinking creatively - even about its business challenges. The idea here is to structure data collection in such a way that you anticipate using that data for BI. One of our vice presidents has made this jump. He develops surveys that will align with existing ERP data, will add valuable and actionable information to his decision making, and are repeatable and repeated every year. This was difficult for him to start because he really needed to focus on the end result before most of the data was collected. Here is a good article that spells out some of the considerations needed to think full circle. You may also want to read some of what Gartner has to say about BI.
These first two are fairly standard keys to success. I've seen a couple of "softer" elements, though, that really make a difference when it comes to BI adoption.
Balancing Quantitative and Qualitative Information
This is where fear creeps in. It seems that many executives I have met are just a little skittish about making decisions based on quantitative analytics. This is the promise of BI, isn't it? Most pitches I see have some version of "cost control through real-time analytics." Our vice president for operations wants real-time analytics on overtime hours so that he can spot trends and possibly curb peaks. That is good stuff. When the idea of basing decisions on quantitative analytics comes up in a group of executives, though, they often balk at it. They see it as a binary choice between basing decisions on the numbers and basing decisions on their experience or knowledge or instinct. This is when we need to step in. I'll extend Jake's recent medical analogy and suggest that we may need to also act as psychologists. It isn't a binary choice; it is both. It is okay to inform your decisions. It is okay to overrule the numbers. Relax . . . just don't be a blinker.
Accepting Incompleteness
This is a tough thing for a lot of people to do. Many people assume that if something is not completely finished it is not usable. When it comes to information, though, being incomplete is natural. Still, when it comes to BI, many consumers will argue that it only gives them "half of the story" or "part of the big picture." That is usually true. I argue that with or without BI, most critical business decisions are made with incomplete information. Even the most complete set of information will still only give an indication of how key areas of your business are performing. (KPI anyone?) The idea here is to understand and accept that BI is incomplete and emerging. It is okay to get your Wabi Sabi on about the big picture and know that it may have blurred edges. After all, most executives I know want to use their own experience and knowledge to fill out the big picture (see above).
If you want to call me out or talk me down, hit the comments section or send me a note. If you prefer to call me out in person, I'll be at Open World , at Circuit in DC , and always at Alliance.
Ted [ linkedin | twitter ] is Vice President for Communications at the Higher Education User Group, MBA and MSIS student at the Johns Hopkins University, Director of Administrative Systems at MICA, and blogger at badgerworks.
Tuesday, September 1, 2009
No OpenWorld For Me: Part II
To say it has been a crazy week or so would be a gross understatement.
Last week, I bowed out from the race to attend Oracle OpenWorld.
Two days later, Justin then Jake then Billy (and here) started a movement to get me there.
All of this in conjunction with 100+ tweets and re-tweets on Twitter. Bradd even got his shirt today. He was one of the first of 15 so far to make the purchase...ostensibly to get my fat ass (Bradd didn't say that) to San Francisco and OOW.
Here's some of the backstory, which Jake alluded to in his post.
The night after Part I, I went to my parents begging for money. Our mortgage was nearly a month late. When I got home that evening, I saw Justin's post and subsequent tweet...I easily separated the 2 events in my head. Borrow money from parents != Community supports my efforts to go to OOW.
Easy right?
Then it came down...How could you do that when you just borrowed money?
I think you know where this is headed.
Unless I win the lottery so that I can pay back all those I owe, I will not be attending OOW this year.
While I think my T-Shirts are really cool, I know many of you (all?) bought them to help me get there. I could not take that money in good faith.
I'd like to donate it to something or someone. It's not a lot, approximately $100 as of right now.
I would like your help in deciding.
I'll repeat myself, to say that I've been humbled by these events would be a gross understatement. Thank you so much for your support...
Last week, I bowed out from the race to attend Oracle OpenWorld.
Two days later, Justin then Jake then Billy (and here) started a movement to get me there.
All of this in conjunction with 100+ tweets and re-tweets on Twitter. Bradd even got his shirt today. He was one of the first of 15 so far to make the purchase...ostensibly to get my fat ass (Bradd didn't say that) to San Francisco and OOW.
Here's some of the backstory, which Jake alluded to in his post.
The night after Part I, I went to my parents begging for money. Our mortgage was nearly a month late. When I got home that evening, I saw Justin's post and subsequent tweet...I easily separated the 2 events in my head. Borrow money from parents != Community supports my efforts to go to OOW.
Easy right?
Then it came down...How could you do that when you just borrowed money?
I think you know where this is headed.
Unless I win the lottery so that I can pay back all those I owe, I will not be attending OOW this year.
While I think my T-Shirts are really cool, I know many of you (all?) bought them to help me get there. I could not take that money in good faith.
I'd like to donate it to something or someone. It's not a lot, approximately $100 as of right now.
I would like your help in deciding.
I'll repeat myself, to say that I've been humbled by these events would be a gross understatement. Thank you so much for your support...
Subscribe to:
Posts (Atom)