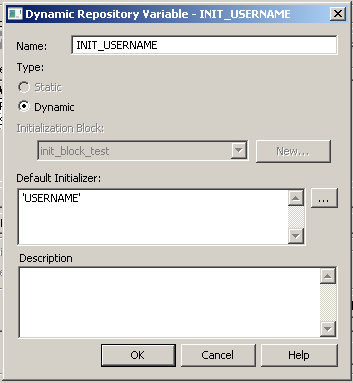
I have a requirement to pull data from a text file. OBI has the ability to pull from (just about) any database, but can it pull from a text file? Of course.
First I'll create a simple file, call it test.txt. In the file I put
cjustice testing
that "space" between cjustice and testing is actually a tab character (usually represented as -> if you have view formatting turned on). Knowing that it is a tab will be important shortly. Save the file to your root folder, i.e. c:\test.txt
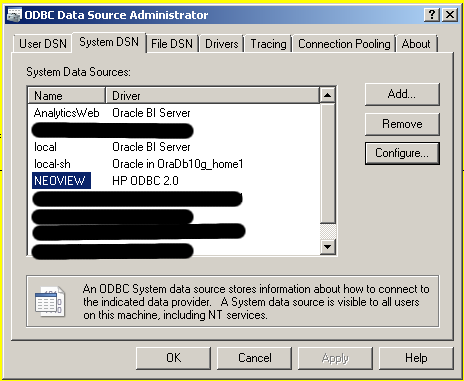
Next up, go to your ODBC Datasources:
Control Panel --> Administrative Tools --> Data Sources (ODBC)
When that opens up, navigate to the System DSN tab and click on Add.
You'll be prompted to choose a driver, select the Microsoft Text Driver (*.txt, *.csv)
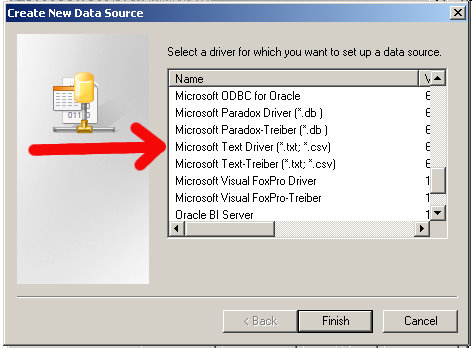
Click on Finish.
Next up, you should see the ODBC Text Setup screen, click on the Options tab to expand the window.
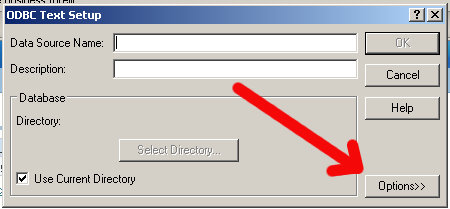
It should look like this:
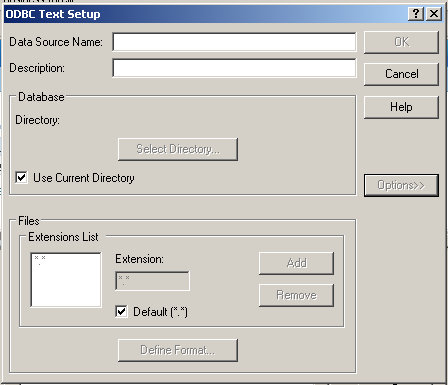
Uncheck the Use Current Directory checkbox (default is usually c:\windows\system32):

Then select the Select Directory button and navigate to your root folder, or the place where you saved the test.txt file. You should see your file, greyed out, in the left hand pane.
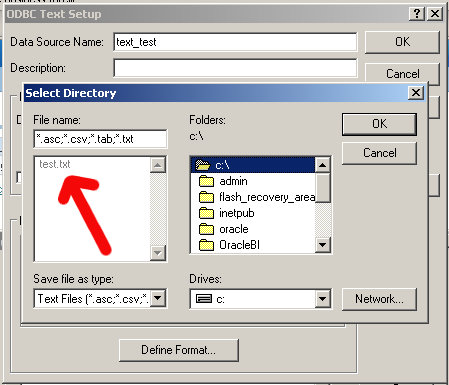
Now, at the bottom of the window, uncheck Default (*.*) which should enable the Define Format button
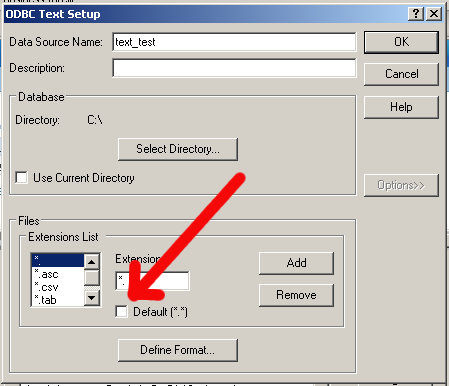
Select the Define Format. For the Format drop down, choose Tab Delimited. Rows to Scan, in my case, will only be 1. You can leave it at the default if you want though.
After you have done that, the Guess button should be enabled for you, go ahead and click it.
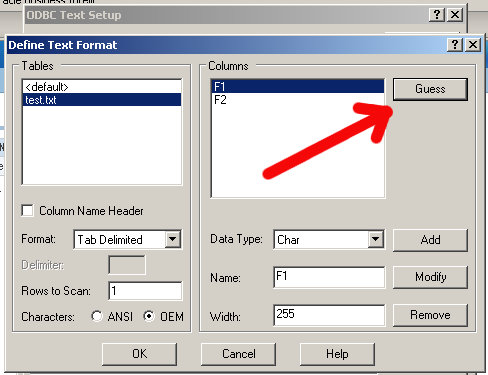
See F1 and F2? Those are your columns. Let's name them something meaningful so we can easily reference them later.
In the Name box, it says F1, enter in USERNAME and click on Modify (the button to the right):
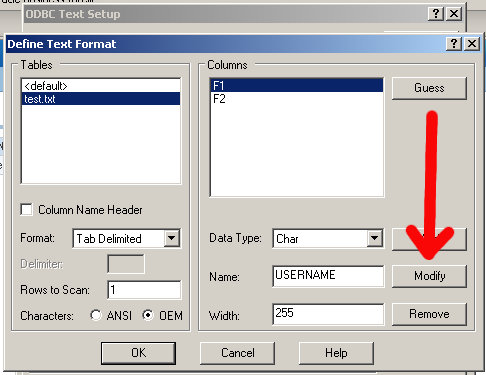
Do the same thing for the F2 column, name it PASSWORD.
It should end up looking like this:

Select OK and then select OK again in the ODBC Text Setup screen. You should now see your new data source in the System DSN window.
 OBI EE Admin Tool
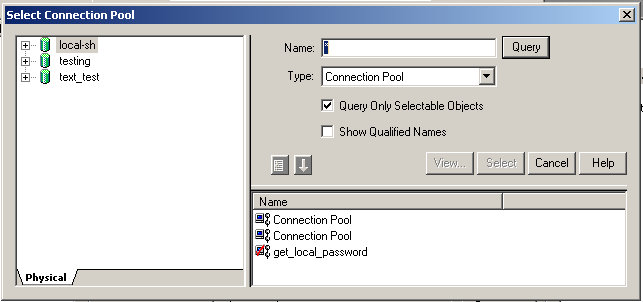
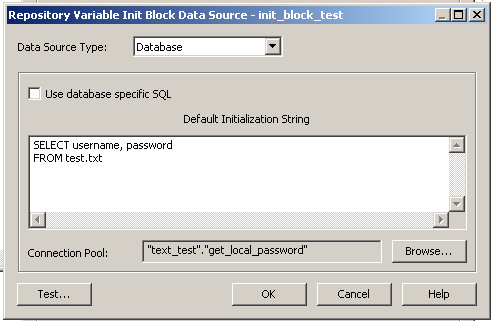
OBI EE Admin ToolNow, we need to pull this new data source into the RPD. Open up your RPD, go to File --> Import --> from Database
You'll see this window, go ahead and select your new data source:
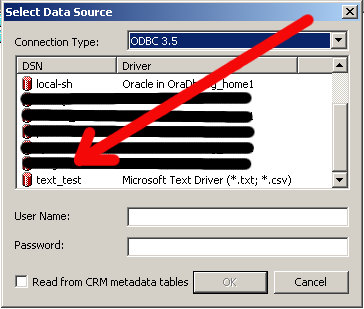
You'll be prompted with the Import window, expand the c:\ drive and then find your file
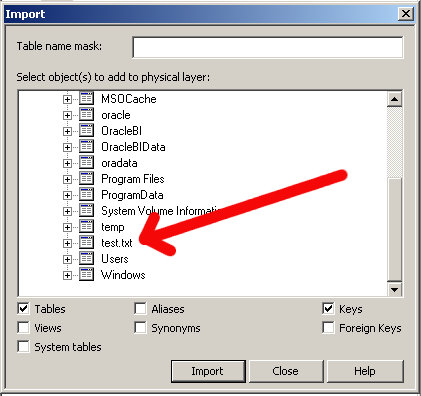
Select Import (at the bottom), wait for it to complete and then close the window. In your physical layer you should see a new "database" with the name "text_test" (or whatever you named your data source). Go ahead and expand that to see what you've got:
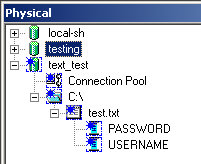
To verify, right click on the table "test.txt" and select View Data.
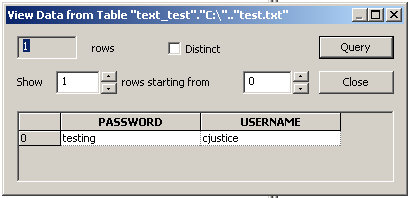
All done.