by Enrique AvilesAs the database performance contact I get to troubleshoot slow queries. Typically when users experience a slow application screen an incident is submitted and the issue ends up on my plate. Recently, I had to investigate a report that was taking a little over 10 minutes to generate results. Although the application is an OLTP system some screens allow users to generate a report that can be sent to the printer. Normally these reports take a few seconds to appear on the screen but this one was way over the application’s SLA requirements.
Below is a sample query construct that captures the syntax of the actual query that was executed by the application. After examining execution plans and generating extended SQL trace I identified the parts highlighted in red as the ones contributing to the query’s poor response time.
SELECT T1.COLUMN_1,
T1.COLUMN_2,
V1.COLUMN_1,
V1.COLUMN_2,
T2.COLUMN_1,
T2.COLUMN_2,
V2.COLUMN_1,
V2.COLUMN_2,
CV.USAGE,
.
.
.
24 additional columns
.
.
.
FROM
TABLE_1 T1,
TABLE_2 T2,
TABLE_3 T3,
TABLE_4 T4,
VIEW_1 V1,
VIEW_2 V2,
COMPLEX_VIEW CV
.
.
An additional mix of 7 tables and views
.
.
WHERE T1.COLUMN_4 = T2.COLUMN_5
AND T2.COLUMN_7 = T3.COLUMN8
.
.
.
AND
CV.PARAMETER_ID = T3.ID
AND CV.PART_ID = T4.ID
AND CV.LOG_DATE = (
SELECT MAX(CV2.LOG_DATE)
FROM COMPLEX_VIEW CV2
WHERE CV2.PART_ID = CV.PART_ID
AND CV2.PARAMETER_ID = CV.PARAMETER_ID
)
AND T5.ID = 'ABC123'
The query’s runtime statistics are:
Elapsed: 00:13:13.01
Statistics
----------------------------------------------------------
4013 recursive calls
6372 db block gets
65682217 consistent gets
858907 physical reads
0 redo size
3328 bytes sent via SQL*Net to client
524 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
3 sorts (memory)
1 sorts (disk)
1 rows processed
The query took more than 13 minutes and over 65 million consistent gets to select one row. This is obviously unacceptable so it is clear why users were not happy with that particular report. What could be causing the query to generate so much work?
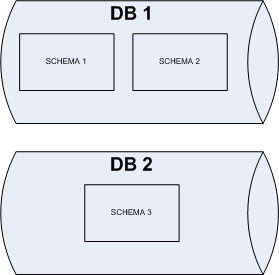
The complex view is composed of twelve tables and 40 lines in the
WHERE clause, five of them
OR conditions. I noticed that removing the subquery that gets the maximum
LOG_DATE from the complex view helped the main query to complete in just a few seconds. Obviously, results were incorrect without the subquery so I had to figure out a way to preserve the logic that gets the maximum
LOG_DATE while having the query complete in a matter of seconds.
Examining the complex view data showed there were no duplicate
LOG_DATEs so the
MAX aggregate function will always return the absolute maximum
LOG_DATE for a given
PART_ID/PARAMETER_ID combination. Finding that characteristic in the data led me to consider using a scalar subquery to get the
USAGE value from the complex view. In the process I also wanted to select from the complex view in one pass so I decided to use the
ROW_NUMBER analytic function to get the maximum
LOG_DATE and eliminate the need for a self-join via a correlated subquery. Having devised that plan, I executed the following query to test what would become the scalar subquery:
SELECT USAGE
FROM (
SELECT CV.USAGE,
ROW_NUMBER() OVER (PARTITION BY CV.PART_ID,
CV.PARAMETER_ID
ORDER BY CV.LOG_DATE DESC) RN
FROM COMPLEX_VIEW CV
WHERE CV.PARAMETER_ID = 'ABC'
AND CV.PART_ID = 'XYZ'
)
WHERE RN = 1
Elapsed: 00:00:00.02
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
738 consistent gets
0 physical reads
0 redo size
532 bytes sent via SQL*Net to client
524 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
1 rows processed
Only 0.02 second and 738 consistent gets to select the
USAGE value from the complex view! It looks like the plan is coming together. I proceeded to replace the correlated subquery with the scalar subquery so the main query becomes:
SELECT T1.COLUMN_1,
T1.COLUMN_2,
V1.COLUMN_1,
V1.COLUMN_2,
T2.COLUMN_1,
T2.COLUMN_2,
V2.COLUMN_1,
V2.COLUMN_2,
(
SELECT USAGE
FROM (
SELECT CV.USAGE,
ROW_NUMBER() OVER (PARTITION BY CV.PART_ID,
CV.PARAMETER_ID
ORDER BY CV.LOG_DATE DESC) RN
FROM COMPLEX_VIEW CV
WHERE CV.PARAMETER_ID = T3.ID
AND CV.PART_ID = T4.ID
)
WHERE RN = 1
) USAGE,
.
.
.
24 additional columns
.
.
.
FROM TABLE_1 T1,
TABLE_2 T2,
TABLE_3 T3,
TABLE_4 T4,
VIEW_1 V1,
VIEW_2 V2,
.
.
An additional mix of 7 tables and views
.
.
WHERE T1.COLUMN_4 = T2.COLUMN_5
AND T2.COLUMN_7 = T3.COLUMN_8
.
.
.
AND T5.ID = 'ABC123'
Notice the complex view is not part of the
FROM section and there are no joins to the complex view in the
WHERE clause. I executed the new and improved query and got the following error:
ERROR at line 17:
ORA-00904: "T4"."ID": invalid identifier
The excitement was extinguished for a brief moment while I realized my mistake. How come
T4.ID is an invalid identifier when I know
ID is a valid column on
TABLE_4? The problem is that
TABLE_4 is not visible inside the inline view of the scalar subquery. The complex view is two levels deep so I can’t join
CV and
T4. How can I hide the logic of the scalar subquery in a way that allows me to join the complex view and
TABLE_4? A view that implements the core logic of the scalar subquery achieves the desired result so I created the following view:
CREATE OR REPLACE VIEW CURRENT_USAGE
AS
SELECT USAGE,
PART_ID,
PARAMETER_ID
FROM
(
SELECT CV.USAGE,
CV.PART_ID,
CV.PARAMETER_ID,
ROW_NUMBER() OVER (PARTITION BY CV.PART_ID,
CV.PARAMETER_ID
ORDER BY CV.LOG_DATE DESC) RN
FROM COMPLEX_VIEW CV
)
WHERE RN = 1;
The main query needs to be modified again to reference the newly created view
CURRENT_USAGE so it becomes:
SELECT T1.COLUMN_1,
T1.COLUMN_2,
V1.COLUMN_1,
V1.COLUMN_2,
T2.COLUMN_1,
T2.COLUMN_2,
V2.COLUMN_1,
V2.COLUMN_2,
(
SELECT USAGE
FROM CURRENT_USAGE CU
WHERE CU.PARAMETER_ID = T3.ID
AND CU.PART_ID = T4.ID
)
USAGE,
.
.
.
24 additional columns
.
.
.
FROM TABLE_1 T1,
TABLE_2 T2,
TABLE_3 T3,
TABLE_4 T4,
VIEW_1 V1,
VIEW_2 V2,
.
.
An additional mix of 7 tables and views
.
.
WHERE T1.COLUMN_4 = T2.COLUMN_5
AND T2.COLUMN_7 = T3.COLUMN_8
.
.
.
AND T5.ID = 'ABC123'
This time around the only surprise was the following runtime statistics:
Statistics
----------------------------------------------------------
2 recursive calls
0 db block gets
28316 consistent gets
0 physical reads
0 redo size
3328 bytes sent via SQL*Net to client
524 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
4 sorts (memory)
0 sorts (disk)
1 rows processed
The new query returned the same data as the original query while performing a fraction of the work. Although 28,316 consistent gets is a bit high to return one row, this value is quite handsome when compared to the original value of 65 million consistent gets. This translates into a 99.96% improvement. Regarding response time, the original query took 13 minutes to complete while the new query only requires 0.3 second to generate results, also a 99.96% improvement.
Combining the right mix of database objects and SQL features helped me achieve such dramatic improvement. I hope my experience will help you consider creative solutions when faced with challenging SQL performance issues.
 On Wednesday, I attended Cary Millsap's Mastering Oracle Trace Data class here in Tampa.
On Wednesday, I attended Cary Millsap's Mastering Oracle Trace Data class here in Tampa.





 Alternate Title: Cary Millsap is Awesomesauce.
Alternate Title: Cary Millsap is Awesomesauce.


 We (
We (