I realized near the end of that post that I had completely screwed it up. I think some of the intent was conveyed, but not really what I wanted. I'm going to try it again.
New sample tables: ONLINE_STORES and ONLINE_STORE_STATUS.
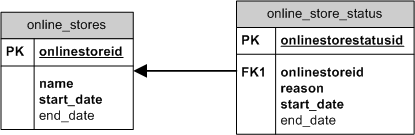
ONLINE_STORES has 4 columns:
- ONLINESTOREID - sequence generated surrogate key
- NAME - String, can be anything really
- START_DATE - When this store went online
- END_DATE - When this store went offline
- ONLINESTORESTATUSID - sequence generated surrogate key
- ONLINESTOREID - FK referencing ONLINE_STORES PK
- REASON - Why was the store de-activated or brought down. Typically I would supply a list of known reasons, but it's unnecessary for my purposes.
- START_DATE - Time the online store was de-activated.
- END_DATE - Time the online store was re-activated.
Similar to the example from Part I, you could do this (find an online store's status) another way be storing the status inline in ONLINE_STORES. Add a column (Persist) STATUS with a check constraint that limits the values to either UP or DOWN, along with a NOT NULL constraint of course.
In a pure OLTP environment that is probably the most efficient solution. Reporting on down times, or better, how long has an online store been UP, is sometimes an afterthought. This can be handled by a shadow/history/audit/logging table. Those have always felt clunky to me.
Many systems are a hybrid of OLTP and reporting (DW/DSS/etc.). My approach has been to tie the two tables together using a View (Derive) to get the answer to whether an online store is UP or DOWN. There might even be a name for that in the modeling books...I should read up.
Here are the scripts necessary for my demo:
CREATE TABLE online_storesNow I just create a simple View on top of these 2 tables:
(
onlinestoreid NUMBER(10)
CONSTRAINT pk_onlinestoreid PRIMARY KEY,
name VARCHAR2(100)
CONSTRAINT nn_name_onlinestores NOT NULL,
start_date DATE DEFAULT SYSDATE
CONSTRAINT nn_startdate_onlinestores NOT NULL,
end_date DATE
);
CREATE TABLE online_store_status
(
onlinestorestatusid NUMBER(10)
CONSTRAINT pk_onlinestorestatusid PRIMARY KEY,
onlinestoreid
CONSTRAINT fk_onlinestoreid_oss REFERENCES online_stores( onlinestoreid )
CONSTRAINT nn_onlinestoreid_oss NOT NULL,
reason VARCHAR2(100)
CONSTRAINT nn_reason_oss NOT NULL,
start_date DATE DEFAULT SYSDATE
CONSTRAINT nn_startdate_oss NOT NULL,
end_date DATE
);
INSERT INTO online_stores
( onlinestoreid,
name )
VALUES
( 1,
'online store #1' );
INSERT INTO online_stores
( onlinestoreid,
name )
VALUES
( 2,
'nerds r us' );
INSERT INTO online_stores
( onlinestoreid,
name )
VALUES
( 3,
'geeks rule' );
CJUSTICE@TESTING>SELECT * FROM online_stores;
ONLINESTOREID NAME START_DAT END_DATE
------------- --------------- --------- ---------
1 online store #1 30-JUL-09
2 nerds r us 30-JUL-09
3 geeks rule 30-JUL-09
3 rows selected.
CREATE OR REPLACECreate a record in ONLINE_STORE_STATUS:
VIEW vw_active_stores
AS
SELECT
os.onlinestoreid,
os.name,
os.start_date,
os.end_date
FROM online_stores os
WHERE NOT EXISTS ( SELECT NULL
FROM online_store_status
WHERE onlinestoreid = os.onlinestoreid
AND ( end_date IS NULL
OR SYSDATE BETWEEN start_date AND end_date ) );
INSERT INTO online_store_statusSelect from the View:
( onlinestorestatusid,
onlinestoreid,
reason )
VALUES
( 1,
1,
'maintenance' );
CJUSTICE@TESTING>SELECT * FROM vw_active_stores;Voila! I Derived!
ONLINESTOREID NAME START_DAT END_DATE
------------- --------------- --------- ---------
3 geeks rule 30-JUL-09
2 nerds r us 30-JUL-09
As a brief sanity check, I created a record that had a pre-determined re-activation date (1 hour forward).
INSERT INTO online_store_statusI'm really not sure which way is better/worse, as with anything I guess "It depends." The semaphore (flag) in ONLINE_STORES is a perfectly viable solution. It is the easiest solution, admittedly. Part of my thinking as well, and this relates back to the question I posed once before, UPDATEs in OLTP: A Design Flaw?. If I UPDATE the record in ONLINE_STORES, it has meaning. Typically it would either be to change the name or set the END_DATE. The UPDATE in ONLINE_STORE_STATUS means something else, it's just telling me the stop time of the DOWN time.
( onlinestorestatusid,
onlinestoreid,
reason,
start_date,
end_date )
VALUES
( 2,
2,
'the geek sliced us...',
SYSDATE - ( 1 / 24 ),
SYSDATE + ( 1 / 24 ) );
CJUSTICE@TESTING>SELECT * FROM vw_active_stores;
ONLINESTOREID NAME START_DAT END_DATE
------------- --------------- --------- ---------
3 geeks rule 30-JUL-09
1 row selected.
Or I am just overthinking this? Is this too much idealism? Is it idealism at all?I've talked about it so much lately I can't remember which way is up. What do you do?
9 comments:
"AND ( end_date IS NULL"
one of the most common causes of awesome bad performance in databases is to assign a meaning to NULL.
You did, and that is why to find out the current status of a store you just did a full scan of the store status table.
Repeat with me 1*(10**99) times:
NULL values are NEVER indexed!
NULL values do not mean anything!
In contravention of the NULL-means-nothing rule, you assigned to it the meaning "this is the current status row". That's why you needed to include it in the view.
Never ever do this.
If you want to flag a particular row of store status as being the "current" status, then do so with a SPECIFIC column.
Call it a semaphore, a flag, whatever, but use it rather than making NULL "mean" something.
Set the semaphore to NULL if it is not, but set it to "Y" or some other significant (read: indexable) value for the "true" case.
And a large percentage of your performance problems will disappear.
Other than that, I see no problems whatsoever with the "Derived" case. It'll work well for OLTP as well as DSS, provided this problem disappears.
I'd probably use the "reason" column as the semaphore: it either has the reason for the store down or a value that says: "it's up". And then index it and use it in the view.
There: no need for special meanings of NULL end_date.
Chet,
Nice post. Simply for the fact that (once again) you cover a topic that is applicable in almost every system.
Noons,
While I can understand the concern about NULLs not being indexed and the (possible) performance implications of the condition "( end_date IS NULL
OR SYSDATE BETWEEN start_date AND end_date )", I do not really think this approach means we are assigning a meaning to NULL.
Setting end_date to NULL (by user, in this case) does seem to closely reflect the business requirement that a we do not know when the particular record (i.e. current) will become a history.
The flag implementation will help in querying data but the constraint (that active flag can only be set for a record whose end_date is NULL or in future) can not be implemented as a CHECK constraint (provided you are not suggesting of making user enter end_date as well as flag, which seems to be a bit overhead for user)(Yes, I know that in a well-implemented system these tables will only be updated with transaction APIs and then it will be trivial to implement this constraint in API, but...).
Also, in this particular example, the data will be queried based on the data that user entered directly as-is (with the approach suggested by Chet) whereas flag will need to be maintained (or derived by the system).
Of course, it all depends upon whether the data is updated more frequently or queried more frequently (in other words, which SLAs, if any, is more important).
After all, this is a classic Type 2 Slowly-Changing Dimensions scenario...
@noons
I hear you with the indexing. I should have mentioned that as one of my concerns.
However, NULL in this case is UNKNOWN, UNDEFINED or NOTHING...I have no idea what it is or what it will be.
In a DW/DSS environment, I've seen the case where the END_DATE (of a record) is set to some pre-determined date in the future (31/12/2999). I think something like that would work (and be indexed), but it will be just filler, an arbitrary value.
Funny, like a good developer, my first thought was, "These tables will never be that big."
I'm going to look at using the semaphore on the ONLINE_STORE_STATUS table, I'm updating it anyway right?
Thanks for your thoughts.
@narendra
I'm still waiting for the post on your installation/configuration of OEL, Oracle and Apex. ;)
Chet,
You must be kidding, right?
In addition to understanding the meaning of all configurations done during installation, when I am able to repeat the entire process with deterministic results, then (and only then) I can have confidence to document it.
First of all, an apology: I did not mean to sound patronizing and now I realize I did. I have a lot of respect for Chet and his posts here.
The meaning-of-NULL thing is simply a heads-up to those who might read this and feel tempted to use it.
@Narendra:
I don't expect end users directly entering data in a table: I assume there is an aplication's code in between.
That indeed is where I'd expect the transformation of "NULL end-date for current period" to "flag it as current".
We can also do that via constraints, triggers, PL/SQL code and so on, at the db level. That would be my preferred option, because I'm a "all-constraints-in-db" kinda guy. But I'll take it at application code level as well.
What I dont want to ever see in a query is: "and (col_name is NULL)". That is a performance killer, unless used for very infrequent reporting purposes where a FTS is acceptable.
@chet:
The use of "magic" values like 31/12/2999 is also quite common and I certainly used those before.
But nowadays it is frowned upon at Oracle: the latest versions of the optimizer assume by default a regular distribution of values in a column up to a max value, explicit in a constraint or implicit in a query.
That last one is the clincher: stick a high "magic" date in a query predicate range and the blessed thing, in the absence of histogram stats, will expect there is a regular distribution of rows all the way up to that date!
If it appears in a range check, it'll cause a FTS 9 times out of 10: it assumes as many rows as there are days between the two dates, and then of course it says to itself: "a full table scan is faster, I'll do that"!
I know, it is a RPITA and I hate it: one of the worst possible optimizer evolutions.
No optimizer should ever *presume* anything about data distribution in the absence of histograms. It is just a bad idea.
But we're stuck with it for the foreseeable future so be aware and avoid it.
Nowadays I am a strong supporter of a flag column: uses hardly any space, only the "Y" case is indexed, all the other rows are set to NULL and use no space in index, etcetc. And the effort to keep it updated is no more nor less than keeping the date column updated any way.
The other possibility is the implicit flag I mentioned: special value of the REASON column. Yes, I know: a "magic" value. But it is a character field and (so far!) those are excluded from optimizer assumptions.
This post is good stuff, Chet. Thanks heaps for all the comments.
A record is created when the store goes down, it can be either a pre-determined amount of time where END_DATE is set to a time in the future (say 30 minutes) or the END_DATE can be NULL and must be manually re-activated
Noons,
This statement made me assume that it might be a requirement to have end date available for user to enter.
@noons
No need to apologize.
I've used the END_DATE many times, in fact it has been my preferred method over the years. Most of my applications have been small though.
That NULL thing has been in the back of my mind for some time and I think you finally made me realize that it wasn't the best way to go. There really is no reason to be afraid of semaphores. Not sure why I haven't liked them either...
That's an interesting note on the optimizer and the "magic" date value. I wonder how that will affect DW design. Actually, I wonder how many people actually know that? I'll have to share that with some DW friends.
chet
"No optimizer should ever *presume* anything about data distribution in the absence of histograms."
Older versions had to assume something. Even the old RBO made assumption about the percentage of rows returned for a predicate.
Dynamic Sampling should do away with the need to assume, but I can't see that getting anything other than a histogram would in a simple case. Where predicates have correlations, it should be better than a histogram.
One thing to watch out for is, if the application starts 'fresh' almost all the data is current. As time goes on, a higher proportion of data becomes old and at some point, you'll find more historical entries than current. Those sort of shifts in data patterns can play hell with execution plans and it is worse if the your skew shifts too. Maybe last year 90% of records were current and 90% of items were blue. This year, 50% of the records are current and 55% of items are blue BUT 90% of current items are green.
Open your wallet, and pay for partitioning.
Post a Comment